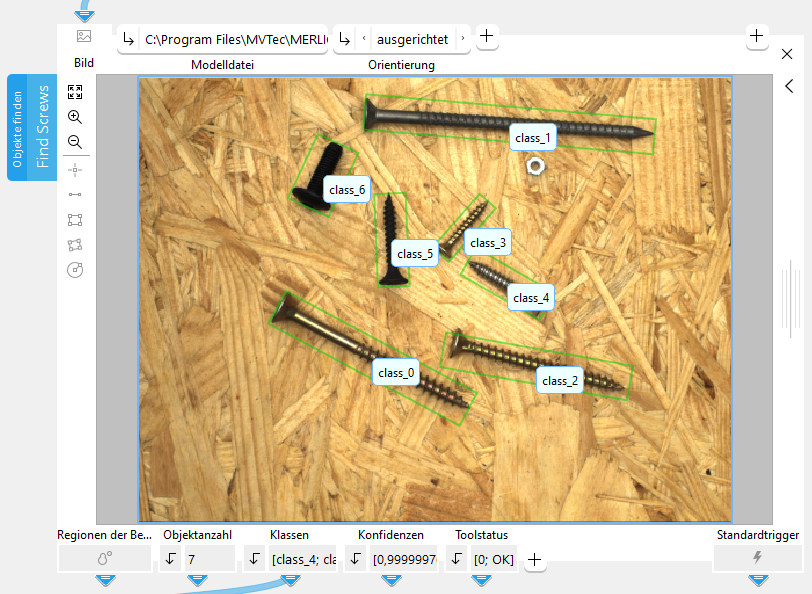
Objekte finden
Mit diesem Tool können Sie Objekte in einem Bild ermitteln, die Objekte einer zuvor definierten Klasse zuordnen und die gefundenen Instanzen der jeweiligen Region im Bild zuweisen. Es spielt keine Rolle, ob sich die Objekte teilweise überlappen.
Dieses Tool benötigt ein Objekterkennungsmodell oder ein Instanzsegmentierungsmodell. Bei einem Objekterkennungsmodell handelt es sich um ein Deep Learning-Modell, das für die Ermittlung von Objektklassen trainiert wurde und diese mit einem umgebenden Rechteck (Begrenzungsrahmen) kennzeichnet.
Um ein Objekterkennungsmodell zu trainieren, können Sie das Deep Learning Tool von MVTec verwenden. Der Workflow sieht folgendermaßen aus: Definieren Sie die Klassen, kennzeichnen Sie Ihre Bilder entsprechend und trainieren Sie schließlich das Objekterkennungsmodell. Durch das Training entsteht ein Objekterkennungsmodell, das für die Ermittlung von Objekten in diesem MERLIC-Tool verwendet werden kann.
Beim Erstellen des Objekterkennungsmodells mit dem MVTec Deep Learning Tool können Sie zwischen zwei Deep Learning-Methoden wählen:
|
Deep Learning-Methode |
Beschreibung |
Verwendung |
|---|---|---|
|
achsenausgerichtete Objekterkennung
|
Bei dieser Methode werden trainierte Objektklassen ermittelt und mit einem Begrenzungsrahmen gekennzeichnet, der parallel zu den Koordinatenachsen ausgerichtet ist. |
Verwenden Sie diese Deep Learning-Methode, wenn Sie Objekte finden und klassifizieren möchten, aber nicht an der Orientierung der betreffenden Objekte interessiert sind. Bei dieser Methode ist der Zeitbedarf für die Kennzeichnung geringer, da die Verarbeitung von achsenausgerichteten Begrenzungsrahmen weniger komplex ist. Die achsenausgerichtete Objekterkennung ist besonders für Objekte geeignet, deren Form leicht in ein achsenausgerichtetes Rechteck eingeschlossen werden kann, z. B. Flaschenverschlusskappen. |
|
ausgerichtete Objekterkennung
|
Bei dieser Methode werden trainierte Objektklassen ermittelt und mit einem Begrenzungsrahmen gekennzeichnet, der in einer beliebigen Richtung ausgerichtet ist. |
Verwenden Sie diese Deep Learning-Methode, wenn Sie nicht nur an der Position der erkannten Objekte, sondern auch an deren Orientierung interessiert sind. Bei dieser Methode ist der Zeitbedarf für die Kennzeichnung größer, da die Verarbeitung von ausgerichteten Begrenzungsrahmen komplexer ist. Wenn Sie diese Methode verwenden, sind die Ergebnisse genauer. Die ausgerichtete Objekterkennung ist besonders für Objekte geeignet, deren Form nicht optimal in ein achsenausgerichtetes Rechteck eingeschlossen werden kann, z. B. diagonal liegende Bleistifte. |
|
Instanzsegmentierung |
Bei dieser Methode wird eine Region um die aktivierte Eingrenzung gezeichnet, in der ein Objekt erkannt wurde. |
Verwenden Sie diese Deep Learning-Methode, wenn Sie pixelgenaue Regionen von Objekten in einem Bild visualisieren möchten. |


Um ein Instanzsegmentierungsmodell zu trainieren, können Sie das Deep Learning Tool von MVTec verwenden. Der Workflow sieht folgendermaßen aus: Erstellen Sie Instanzen basierend auf Polygonen und Masken. Erfahrungsgemäß sollten Sie Polygone verwenden, wenn die Instanz des Objekts aus größeren Flächen mit geraden Linien besteht, und Masken verwenden, wenn das Objekt kleiner ist oder eine Instanz korrigiert werden muss. Trainieren Sie schließlich das Instanzsegmentierungsmodell.
Durch das Training entsteht ein Instanzsegmentierungsmodell, das für die Ermittlung von Objekten in diesem MERLIC-Tool verwendet werden kann. Die Objekte werden dann in die zuvor definierten Klassen kategorisiert, und die gefundenen Instanzen werden der jeweiligen Region im Bild zugewiesen.
Weitere Informationen zum Erstellen eines Deep Learning-Modells finden Sie in der Dokumentation des MVTec Deep Learning Tools. Obwohl es auch möglich ist, das Deep Learning-Modell mit MVTec HALCON zu trainieren, wird empfohlen, das MVTec Deep Learning Tool zu verwenden.
Wenn eine Deep Learning-Modelldatei verfügbar ist, können Sie die Datei sofort in diesem MERLIC-Tool verwenden.
Unterstützung von Artificial Intelligence Acceleration-Schnittstellen (AI²)
MERLIC umfasst Artificial Intelligence Acceleration-Schnittstellen (AI²) für das NVIDIA® TensorRT™ SDK und die Intel® Distribution of OpenVINO™ toolkit. Das heißt, Sie können KI-Beschleuniger-Hardware als Recheneinheit verwenden, die kompatibel mit NVIDIA® TensorRT™ oder dem OpenVINO™ toolkit ist, um optimierte Inferenzberechnungen auf der jeweiligen Hardware durchzuführen, z. B. auf NVIDIA®-GPUs oder Hardware, die das OpenVINO™ toolkit unterstützt, wie CPUs, Intel®-GPUs und Movidius™-VPUs. Dadurch können Sie Deep Learning-Inferenzberechnungen erheblich beschleunigen. Die jeweilige Hardware kann beim Toolparameter „Recheneinheit“ ausgewählt werden.
Voraussetzungen
NVIDIA®-GPUs und CPUs, die das OpenVINO™ toolkit unterstützen, können sofort nach der Installation von MERLIC verwendet werden. Eine zusätzliche Installation oder Einrichtung ist nicht erforderlich.
Für die Verwendung von Intel®-GPUs und VPUs mit dem OpenVINO™ toolkit als Recheneinheit gelten die folgenden Voraussetzungen:
- Zuerst müssen Sie die Intel® Distribution of OpenVINO™ toolkit installieren.
- Sie müssen MERLIC in einer OpenVINO™ toolkit-Umgebung starten.
Weitere Informationen zu Installation und Voraussetzungen finden Sie unter AI²-Schnittstellen für Tools mit Deep Learning.
Parameter
Standardparameter
Bild:
Dieser Parameter stellt das Bild dar, in dem Objekte erkannt werden sollen.
Modelldatei:
Dieser Parameter definiert das HALCON Deep Learning-Modell (.hdl-Dateiformat), das zum Erkennen von Objekten verwendet werden soll. Standardmäßig ist kein Modell definiert. Um dieses Tool verwenden zu können, muss jedoch ein Deep Learning-Modell definiert werden.
Obwohl es auch möglich ist, das Objekterkennungsmodell mit MVTec HALCON zu trainieren, wird empfohlen, das MVTec Deep Learning Tool zu verwenden.
Dieses Tool unterstützt nur Deep Learning-Modelle, die mit den Standardwerten für die folgenden Vorverarbeitungsparameter trainiert wurden:
- NormalizationType = "none"
- DomainHandling = "full_domain"
Orientierung:
Dieser Parameter bietet die Möglichkeit, die Orientierung für die entstehenden Begrenzungsrahmen anzugeben. Die jeweilige Auswahl beeinflusst die Ergebnisse „X“, „Y“ und „Winkel“. Diese Ergebnisse geben die erforderlichen Daten zum Bestimmen der räumlichen Orientierung der Objekte aus.
Wenn Sie das Objekterkennungsmodell mit dem MVTec Deep Learning Tool trainieren, können Sie auswählen, ob das Modell mit achsenausgerichteten Begrenzungsrahmen oder mit ausgerichteten Begrenzungsrahmen trainiert werden soll. Wenn Sie das Objekterkennungsmodell mit ausgerichteten Begrenzungsrahmen trainiert haben, bietet dieser Parameter die Möglichkeit, die Begrenzungsrahmen an den Achsen auszurichten. Wenn Sie das Objekterkennungsmodell mit achsenausgerichteten Begrenzungsrahmen trainiert haben, ist es nicht möglich, die Begrenzungsrahmen ausgerichtet auszurichten.
Der Parameter ist standardmäßig auf „achsenausgerichtet“ festgelegt.
|
Wert |
Beschreibung |
|---|---|
|
achsenausgerichtet |
Die Begrenzungsrahmen werden als achsenausgerichtete Rechtecke angegeben. |
|
ausgerichtet |
Die Begrenzungsrahmen werden als ausgerichtete Rechtecke angegeben. Wenn das Objekterkennungsmodell mit achsenausgerichteten Begrenzungsrahmen trainiert wurde, hat dieser Parameterwert keine Auswirkung. |
Zusätzliche Parameter
Klassenselektor:
Dieser Parameter filtert die Ergebnisse. Sie können eine von drei verschiedenen Filteroptionen auswählen: Der Parameter ist standardmäßig auf „alle Klassen“ festgelegt.
|
Wert |
Beschreibung |
|---|---|
|
alle Klassen |
Das Tool erkennt alle verfügbaren Klassen. |
|
nur Klasse <Klassenname> |
Das Tool erkennt nur die ausgewählte Klasse. Die Klasse kann aus allen verfügbaren Klassen ausgewählt werden. |
|
alle außer <Klassenname> |
Das Tool erkennt alle verfügbaren Klassen außer der ausgewählten Klasse. Die Klasse kann aus allen verfügbaren Klassen ausgewählt werden. |
Maximale Anzahl an Objekten:
Dieser Parameter definiert die maximale Anzahl an Objekten, die vom Deep Learning-Modell erkannt werden können. Sie können diesen Parameter verwenden, um den Wert zu überschreiben, der beim Training des Deep Learning-Modells verwendet wurde.
Der Parameter wird beim Laden des Modells automatisch auf den Maximalwert festgelegt, der in der Modelldatei gespeichert ist. Geben Sie die gewünschte maximale Anzahl an Objekten in das Eingabefeld des Parameters ein oder verwenden Sie den Schieberegler, um den Wert festzulegen, wenn Sie einen anderen Wert verwenden möchten. Mit dem Schieberegler können lediglich Werte bis 20 festgelegt werden. Wenn mehr als 20 Objekte gefunden werden sollen, müssen Sie den Wert manuell in das Eingabefeld eingeben.
Die Objekte werden in der Reihenfolge ihrer Konfidenzwerte sortiert. Wenn die Anzahl der Objekte in einem Bild größer ist als der im diesem Parameter definierte Wert, werden Objekte mit der geringsten Konfidenz ausgeschlossen, bis die Anzahl der erkannten Objekte mit dem in „Maximale Anzahl an Objekten“ definierten Wert übereinstimmt.
Im Ergebnis „Objektanzahl“ können Sie feststellen, wie viele Objekte in einem Bild erkannt wurden.
Minimalkonfidenz:
Dieser Parameter bestimmt die minimale Konfidenz, die ein Objekt erreichen muss, um erkannt zu werden. Alle Objekte mit einem Konfidenzwert, der kleiner ist als der Wert von „Minimalkonfidenz“, werden nicht erkannt. Der Parameter ist standardmäßig auf 0,5 festgelegt.
Überlappung gleicher Klassen:
Dieser Parameter legt die maximal zulässige Überlappung von erkannten Objekten der gleichen Klasse fest. Das heißt: Wenn sich zwei Objekte derselben Klasse überlappen und diese Überlappung den Wert des Parameters „Überlappung gleicher Klassen“ übersteigt, wird das Objekt mit der geringeren Konfidenz nicht erkannt. Dies ist nützlich, wenn das Objekterkennungsmodell mehrere aussichtsreiche Instanzen für das gleiche Objekt findet oder zwei Instanzen des gleichen Objekts sehr nah beieinander liegen. Der Parameter ist standardmäßig auf 0,5 festgelegt.
Überlappung unterschiedlicher Klassen:
Dieser Parameter legt die maximal zulässige Überlappung von erkannten Objekten verschiedener Klassen fest. Das heißt: Wenn sich zwei Objekte verschiedener Klassen überlappen und diese Überlappung den Wert des Parameters „Überlappung unterschiedlicher Klassen“ übersteigt, wird das Objekt mit der geringeren Konfidenz nicht erkannt. Der Parameter ist standardmäßig auf 1 festgelegt.
Recheneinheit:
Dieser Parameter definiert die Einheit, die für die Verarbeitung der Bilder verwendet wird. Der Parameter ist standardmäßig auf „auto“ festgelegt. In diesem Modus versucht MERLIC, eine geeignete GPU als Recheneinheit auszuwählen, da deren Leistung in der Regel besser ist als die der CPU. Der verfügbare Speicher in der betreffenden GPU muss jedoch mindestens 4 GB groß sein. Wird keine geeignete GPU gefunden, wird ersatzweise die CPU verwendet.
Sie können die Recheneinheit auch manuell auswählen. Klicken Sie auf den Parameter, um die Einheit in der Liste aller verfügbaren Recheneinheiten auszuwählen. Wenn Sie eine GPU als Recheneinheit auswählen, sollten Sie überprüfen, ob genügend Speicher für das verwendete Deep Learning-Modell verfügbar ist. Anderenfalls kann es zu unerwünschten Effekten kommen, z. B. langsamere Inferenzberechnungen.
MERLIC unterstützt auch die Verwendung von KI-Beschleuniger-Hardware, die mit dem NVIDIA® TensorRT™ SDK oder dem OpenVINO™ toolkit kompatibel ist:
- NVIDIA®-GPUs
- CPUs, Intel®-GPUs, Intel®-VPUs (MYRIAD und HDDL), die das OpenVINO™ toolkit unterstützen
Die jeweiligen Einheiten werden mit dem Präfix „TensorRT(TM)“ oder „OpenVINO(TM)“ gekennzeichnet. Wenn Sie eine Einheit auswählen, die NVIDIA® TensorRT™ oder das OpenVINO™ toolkit unterstützt, wird der Speicher in der Einheit über das jeweilige Plugin für die AI²-Schnittstelle initialisiert.
Sobald eine KI-Beschleuniger-Hardware als Recheneinheit ausgewählt wurde, wird die Optimierung des Deep Learning-Modells gestartet. Nach der Optimierung werden alle Parameter, die Modellparameter darstellen, intern als schreibgeschützt festgelegt. Die betreffenden Werte können daher nicht mehr geändert werden, solange der ausgewählte KI-Beschleuniger als Recheneinheit verwendet wird. Um die Parameter zu ändern, müssen Sie zuerst eine andere Recheneinheit ohne KI-Beschleunigung auswählen. Nachdem die Parameter festgelegt wurden, können Sie die entsprechende KI-Beschleuniger-Hardware wieder als Recheneinheit verwenden.
CPUs, die das OpenVINO™ toolkit unterstützen, können ohne zusätzliche Installationsschritte verwendet werden. Sie werden automatisch in die Liste der verfügbaren Recheneinheiten aufgenommen. Wenn mehrere Recheneinheiten mit demselben Namen verfügbar sind, wird den Namen eine Indexnummer zugewiesen. Gleiches gilt für GPUs, die NVIDIA® TensorRT™ unterstützen.
Um GPUs und VPUs, die das OpenVINO™ toolkit unterstützen, als Recheneinheit verwenden zu können, muss die Intel® Distribution of OpenVINO™ toolkit auf dem jeweiligen Computer installiert sein. Außerdem muss MERLIC in einer OpenVINO™ toolkit-Umgebung gestartet werden. Ausführlichere Informationen zu den Voraussetzungen finden Sie unter AI²-Schnittstellen für Tools mit Deep Learning.
Neben der Optimierung über KI-Beschleuniger-Hardware unterstützt MERLIC weitere dynamische Optimierungen über das NVIDIA® CUDA® Deep Neural Network (cuDNN). Diese Optimierung kann über die MERLIC-Einstellungen im MERLIC Creator aktiviert werden. Weitere Informationen finden Sie unter MERLIC-Einstellungen.
Präzision:
Dieser Parameter legt den Datentyp fest, der intern für die Optimierung des Deep Learning-Modells für Inferenz verwendet wird, d. h., er legt die Präzision fest, mit der das Modell konvertiert wird. Die Standardeinstellung ist „hoch“.
Die folgende Tabelle zeigt die Einstellungen für die Modellpräzision, die in diesem Tool unterstützt werden.
|
Wert |
Beschreibung |
|---|---|
|
hoch |
Das Deep Learning-Modell wird mit „float32“-Präzision konvertiert. |
|
mittel |
Das Deep Learning-Modell wird mit „float16“-Präzision konvertiert. |
Die meisten Recheneinheiten unterstützen beide Präzisionseinstellungen. Es gibt jedoch u. U. auch einige Recheneinheiten, die nur eine dieser Einstellungen unterstützen. In diesem Fall ist für den Parameter nur die unterstützte Präzision verfügbar, nachdem das jeweilige Gerät mit dem Parameter „Recheneinheit“ ausgewählt wurde. Bei einer automatischen Auswahl der Recheneinheit, d. h. bei Einstellung von „Recheneinheit“ auf „auto“, ist nur die Präzision „hoch“ verfügbar.
Ergebnisse
Standardergebnisse
Regionen der Begrenzungsrahmen:
Dieses Ergebnis gibt die Begrenzungsrahmen der erkannten Objekte als Regionen aus.
Objektanzahl:
Dieses Ergebnis gibt die erkannten Objekte unabhängig von ihrer Klasse aus.
Klassen:
Dieses Ergebnis gibt die Klassennamen aller erkannten Objekte aus. Sie werden als Tupel in der Reihenfolge ihrer Konfidenz ausgegeben. Das Tupel enthält dieselbe Anzahl von Zeichenfolgen (Klassen) wie der Wert des Ergebnisses „Objektanzahl“.
Konfidenzen:
Dieses Ergebnis gibt einen numerischen Wert aus, der die Wahrscheinlichkeit angibt, dass die erkannten Objekte zu der jeweils zugewiesen Klasse gehören. Wenn der Parameter den Wert 1 aufweist, stimmt das gefundene Objekt mit einer Genauigkeit von 100 % mit der trainierten Klasse überein. Wird mehr als ein Objekt gefunden, werden die zugehörigen Konfidenzen als Tupel in der Reihenfolge ihrer Konfidenz ausgegeben.
Toolstatus:
„Toolstatus“ gibt Informationen zum Status des Tools aus und kann daher für die Fehlerbehandlung verwendet werden. Weitere Informationen zu den verschiedenen Toolstatus-Ergebnissen finden Sie unter Toolstatus-Ergebnis.
Zusätzliche Ergebnisse
Konturen der Begrenzungsrahmen:
Dieses Ergebnis gibt die Begrenzungsrahmen der erkannten Objekte als Konturen aus.
Objekt Instanzen:
Dieses Ergebnis gibt eine Region um die aktivierte Eingrenzung aus, in der ein Objekt erkannt wurde. Beachten Sie, dass dieses Ergebnis nur verwendet werden kann, wenn eine Modelldatei für die Instanzsegmentierung ausgewählt wurde.
X:
Dieses Ergebnis enthält die X-Koordinaten der Zentrumspunkte der Begrenzungsrahmen aller erkannten Objekte sortiert nach Konfidenz. Sie werden in Pixel angegeben und als Tupel in der Reihenfolge ihrer Konfidenz ausgegeben. Das Tupel enthält dieselbe Anzahl von X-Koordinaten wie der Wert des Ergebnisses „Objektanzahl“.
Y:
Dieses Ergebnis enthält die Y-Koordinaten der Zentrumspunkte der Begrenzungsrahmen aller erkannten Objekte sortiert nach Konfidenz. Sie werden in Pixel angegeben und als Tupel in der Reihenfolge ihrer Konfidenz ausgegeben. Das Tupel enthält dieselbe Anzahl von Y-Koordinaten wie der Wert des Ergebnisses „Objektanzahl“.
Winkel:
Dieses Ergebnis gibt die Winkel von Begrenzungsrahmen der erkannten Objekte aus. Diese bestimmen Umfang und Richtung der Drehung der Begrenzungsrahmen. Die Winkel werden in Grad als reelle Zahlen und als Tupel in der Reihenfolge ihrer Konfidenz ausgegeben. Das Tupel enthält dieselbe Anzahl von Winkeln wie der Wert des Ergebnisses „Objektanzahl“.
|
Wert |
Beschreibung |
|---|---|
|
0 |
Das Rechteck wird nicht gedreht. |
|
1 bis 180 |
Das Rechteck wird gegen den Uhrzeigersinn gedreht. |
|
-1 bis -180 |
Das Rechteck wird im Uhrzeigersinn gedreht. |
Dieses Ergebnis gibt nur Winkel aus, wenn das für die Objekterkennung verwendete Deep Learning-Modell mit ausgerichteten Begrenzungsrahmen trainiert wurde und der Parameter „Orientierung“ auf „ausgerichtet“ festgelegt ist. Wenn Sie achsenausgerichtete Begrenzungsrahmen verwenden, weist das Ergebnis den Wert „0,0“ auf.
Verwendete Recheneinheit:
Dieses Ergebnis gibt die Recheneinheit aus, die in der letzten Iteration verwendet wurde. Anhand dieses Ergebnisses können Sie feststellen, welche Recheneinheit tatsächlich verwendet wurde, wenn der Parameter „Recheneinheit“ auf „auto“ festgelegt ist, bzw. überprüfen, ob die richtige Recheneinheit verwendet wurde.
Datentyp der Präzision:
Dieses Ergebnis gibt den Datentyp aus, der intern für die Optimierung des Deep Learning-Modells für Inferenz verwendet wurde. Anhand dieses Ergebnisses können Sie überprüfen, ob die richtige Präzision verwendet wurde, falls Probleme auftreten.
Wenn der Parameter „Präzision“ auf „hoch“ festgelegt ist, soll das Deep Learning-Modell mit „float32“-Präzision konvertiert werden. Daher wird erwartet, dass dieses Ergebnis den Datentyp „float32“ ausgibt. Wenn der Parameter „Präzision“ auf „mittel“ festgelegt ist, soll das Deep Learning-Modell mit „float16“-Präzision konvertiert werden. In diesem Fall werden für das Ergebnis Werte des Datentyps „float16“ erwartet. Falls bei einer Iteration Ihrer MVApp ein Problem aufgetreten ist, können Sie überprüfen, ob dieses Ergebnis einen anderen Datentyp als erwartet ausgibt. Weitere Informationen finden Sie möglicherweise auch in der Log-Datei. Weitere Informationen zu den Log-Dateien finden Sie auf der Seite Protokollieren.
Verarbeitungszeit:
Dieses Ergebnis gibt die Dauer der letzten Ausführung des Tools in Millisekunden aus. Das Ergebnis wird als zusätzliches Ergebnis bereitgestellt. Es ist daher standardmäßig ausgeblendet, kann aber über die Schaltfläche ![]() neben den Toolergebnissen angezeigt werden. Weitere Informationen finden Sie im Abschnitt Verarbeitungszeit in der Tool-Referenz-Übersicht.
neben den Toolergebnissen angezeigt werden. Weitere Informationen finden Sie im Abschnitt Verarbeitungszeit in der Tool-Referenz-Übersicht.
Anwendungsbeispiele
Dieses Tool wird in den folgenden MERLIC-Vision-App-Beispielen verwendet:
- find_and_count_screw_types.mvapp
- segment_pills_by_shape.mvapp

