查找对象
使用该工具可根据预先训练好的深度学习模型对图像中的对象进行定位和分类。您可以使用深度学习模型进行对象检测或实例分割。
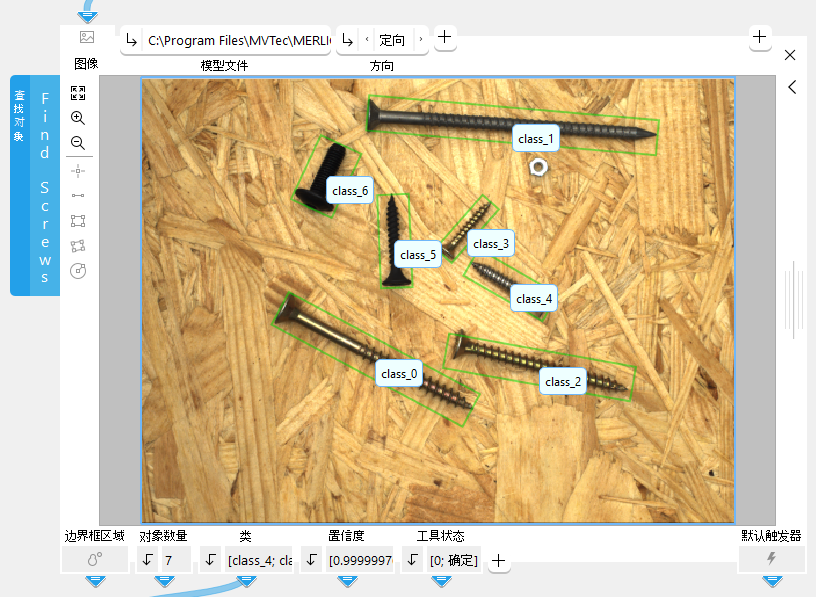
对象检测模型和实例分割模型都能检测到指定类的对象,并在图像中找到它们。这些对象可以朝任何方向,也可以部分重叠。每个检测到的对象的位置上都会标注一个边界框,即围绕着相应对象的矩形。每个边界框都会返回一个置信度值,表示边界框内的对象属于指定类的可能性有多大。实例分割是一种特殊的对象检测,在这种情况下,模型也会预测不同的对象实例,并将找到的实例分配到图像中的相应区域。因此,除了边界框和置信度值之外,还可以获得检测到的对象的像素精度区域。
如果有深度学习模型文件,您可以直接在此 MERLIC 工具中使用它。否则,您首先要训练一个模型。
训练深度学习模型
您可以使用 MVTec 的Deep Learning Tool来训练用于该工具的深度学习模型。创建新的训练项目时,必须选择所需的深度学习方法。如果要训练用于该工具的深度学习模型,可以选择以下方法:
|
深度学习方法 |
描述 |
|---|---|
|
轴平行对象检测
|
这种方法用平行于坐标轴的边界框标记每个检测到的对象的位置。 因此,它特别适用于形状可以很容易地被轴平行矩形包围的对象,如瓶盖。 如果您只对对象的位置感兴趣,而对其方向不感兴趣,则可以使用这种方法。 此外,这种方法可以节省标记时间,因为与轴平行的边界框使用起来没那么复杂。
|
|
定向对象检测 |
这种方法用定向边界框标记每个检测到的对象的位置。 因此,它特别适用于形状无法被轴平行矩形最佳地包围的倾斜对象,如对角放置的铅笔。 如果您不仅对检测到的对象的位置感兴趣,还对它们的方向感兴趣,可以使用这种方法。对象的边界框会指向相应的方向。 使用此方法时,结果将更准确。然而您需要更多时间进行标记,因为定向的边界框使用起来更加复杂。
|
|
实例分割
|
这种方法用平行于坐标轴的边界框标记每个检测到的对象的位置。此外,它还会预测并返回每个检测到的对象实例的区域。 如果您想区分同一类别的多个实例,并可视化图像中对象实例的像素精度区域,可以使用这种方法。
|



选择深度学习方法后,工作流程通常如下:
- 创建标签类。
- 为图像、对象或区域分配标签。如果使用实例分割模型,还必须根据多边形或遮罩创建实例。
- 训练模型。
随后可在这些 MERLIC 工具中将经过训练的深度学习模型用作参数“模型文件”的输入。
虽然也可以使用 MVTec HALCON 来训练深度学习模型,但建议使用 MVTec Deep Learning Tool。有关如何创建深度学习模型的更多信息,请参阅 MVTec Deep Learning Tool 的文档。
Artificial Intelligence Acceleration 接口 (AI²) 的支持
MERLIC 附带用于 NVIDIA® TensorRT™ SDK 和 Intel® Distribution of OpenVINO™ toolkit 的 Artificial Intelligence Acceleration 接口 (AI²)。因此,您可以将 AI 加速器硬件用作与 NVIDIA® TensorRT™ 或 OpenVINO™ toolkit 兼容的处理单元,以便在相应的硬件上执行优化的推理。通过这种方式,您可以显著加快深度学习推理时间。相应的硬件可在工具参数“处理单元”中选择。
有关安装和前提条件的更多详细信息,请参阅 用于具有深度学习功能的工具的 AI² 接口 主题。
参数
基本参数
图像:
此参数表示应检测对象的图像。
模型文件:
此参数定义用于检测对象的深度学习模型(.hdl 文件格式)。默认情况下未定义任何模型。但是,必须定义一个深度学习模型才能使用此工具。
如果要使用由 MERLIC 的 AI² 接口支持的特定 AI 加速器硬件,则可以使用针对相应设备优化的深度学习模型。这样可以缩短 MVApp 的加载时间,并减少模型所需的内存量。
我们建议使用 MVTec Deep Learning Tool 来训练模型。导出模型时,可以选择为 AI² 接口优化模型。不过,如果仍想使用 MVTec HALCON 进行训练,则必须考虑以下对预处理参数的限制。
此工具仅支持使用以下预处理参数的默认值训练的深度学习模型:
- NormalizationType = "none"
- DomainHandling = "full_domain"
方向:
此参数允许您指定生成的边界框的方向。如果您使用通过定向边界框训练的对象检测模型,那么通过该参数可以将所生成边界框的方向更改为轴平行。但是,如果模型是通过轴平行边界框训练的,则无法更改边界框的方向。此时,该参数将被停用,其值将显示为灰色。
默认情况下,该参数设置为“轴平行”。
|
值 |
描述 |
|---|---|
|
轴平行 |
边界框作为轴平行矩形提供。使用此设置时,“角度”结果中返回的所有值都将是 0.0。 |
|
定向 |
边界框作为定向矩形提供。 只有在使用为定向对象检测而训练的模型文件时,才能设置该参数值。 |
其他参数
类选择器:
此参数会筛选结果。您可以在三个不同的筛选选项之间进行选择。默认情况下,该参数设置为“所有类”。
|
值 |
描述 |
|---|---|
|
所有类 |
工具会检测所有可用类。 |
|
唯一类 <类名称> |
工具只会检测选定的类。选定的类可从所有可用的类中选择。 |
|
全部但不含 <类名称> |
工具会检测除所选类之外的所有可用类。选定的类可从所有可用的类中选择。 |
最大对象数量:
此参数定义可被深度学习模型检测到的最大对象数量。您可使用此参数覆盖在训练深度学习模型过程中使用的相应值。
在加载模型文件时,此参数会自动设置为存储在模型文件中的最大值。要使用其他值,请在参数输入字段输入所需的最大对象数量,或使用滑块设置值。使用滑块只能设置不超过 20 的值。如果您希望找出 20 个以上对象,请在输入字段中手动输入。
将按其置信度值为对象排序。如果图像中的对象数量高于此参数定义的值,将排除置信度最低的对象,直到检测出的对象数与“最大对象数量”中定义的值相符。
在结果“对象数量”中,您可以看到图像中检测到多少对象。
最小置信度值:
此参数确定对象必须至少达到多少置信度才能被检测到。置信度值低于定义的“最小置信度值”的所有对象都不会被检测到。默认情况下,此参数设置为 0.5。
相同类的重叠:
此参数设置检测到的同类对象的最大允许重叠。这表示,如果两个同类的对象重叠,并且此重叠超过了“相同类的重叠”参数的值,则置信度较低的对象将不会被检测到。如果您的对象检测模型为同一个对象找到了几个可能的实例,或者如果两个相同的对象彼此非常接近,这将很有用。默认情况下,此参数设置为 0.5。
不同类的重叠:
此参数设置检测到的不同类对象的最大允许重叠。这表示,如果两个不同类的对象重叠,并且此重叠超过了“不同类的重叠”参数的值,则置信度较低的对象将不会被检测到。默认情况下,此参数设置为 1。
处理单元:
此参数定义用于处理图像的方法。默认情况下,此参数设置为“自动”。在此模式下,MERLIC 尝试选择合适的 GPU 作为处理单元,因为它通常比 CPU 性能更好。然而,这需要相应 GPU 拥有至少 4 GB 的可用内存。如果没有找到合适的 GPU,CPU 将用作后备。
您也可以手动选择处理单元。单击此参数,从所有可用处理单元列表中选择设备。如果选择 GPU 作为处理单元,我们建议您检查是否有足够的内存可用于所使用的深度学习模型。否则,可能会出现推理速度较慢等不良影响。
MERLIC 还支持使用与 NVIDIA® TensorRT™ SDK 或 OpenVINO™ toolkit 兼容的 AI 加速器硬件:
- NVIDIA® GPU
- 支持 OpenVINO™ toolkit 的 CPU、Intel® GPU、Intel® VPU(MYRIAD 和 HDDL)
相应设备用前缀“TensorRT(TM)”或“OpenVINO(TM)”标记。如果您选择支持 NVIDIA® TensorRT™ 或 OpenVINO™ toolkit 的设备,内存将通过 AI² 接口的相应插件在设备上初始化。
选择 AI 加速器硬件作为处理单元后,即开始深度学习模型的优化。优化后,表示模型参数的所有参数将在内部设置为只读。因此,只要选定的 AI 加速器用作处理单元,就无法再更改它们的值。要更改参数,首先必须将处理单元更改为没有任何 AI 加速的其他处理单元。设置参数后,可以将处理单元设置回相应的 AI 加速器硬件。
支持 OpenVINO™ toolkit 的 CPU 无需任何额外的安装步骤即可使用。它们将自动出现在可用处理单元列表中。如果有多个具有相同名称的处理单元可用,则会为其名称指定一个索引号。这同样适用于支持 NVIDIA® TensorRT™ 的 GPU。
要将支持 OpenVINO™ toolkit 的 GPU 和 VPU 用作处理单元,计算机上必须安装 Intel® Distribution of OpenVINO™ toolkit,并且必须在 OpenVINO™ toolkit 环境中启动 MERLIC。请参阅 用于具有深度学习功能的工具的 AI² 接口以了解有关前提条件的更多详细信息。
除了通过 AI 加速器硬件进行优化外,MERLIC 还支持通过 NVIDIA® CUDA® Deep Neural Network (cuDNN) 进行进一步的动态优化。此优化可通过 MERLIC Creator 中的 MERLIC 设定来启用。有关更多信息,请参阅MERLIC 设定主题。
精度:
此参数定义内部用于优化推理深度学习模型的数据类型,它定义了模型转换的精度。默认情况下设置为“高”。
下表显示此工具支持的模型精度。
|
值 |
描述 |
|---|---|
|
高 |
深度学习模型转换为“float32”的精度。 |
|
中等 |
深度学习模型转换为“float16”的精度。 |
大部分处理单元支持两种精度类型。然而,可能有一些处理单元只支持其中一种精度。在这种情况下,在参数“处理单元”中选择相应的设备后,参数中只有受支持的精度可用。如果自动选择处理单元,即如果“处理单元”设置为“自动”,则只有精度“高”可用。
结果
基本结果
边界框的区域:
此结果将检测到的对象的边界框作为区域返回。
对象数量:
此结果返回检测到的对象的数量,而无论其属于哪个类。
类:
此结果返回所有检测到的对象的类名称。它们以元组的形式按其置信度顺序返回。它包含与“对象数量”结果的值相同数量的字符串,即类。
置信度:
此结果返回一个数值,指示检测到的对象属于分配给它们的类的可能性。如果该参数的值为 1,已发现对象与已训练类之间的匹配准确性为 100%。如果找到多个对象,相应的置信度会以元组的形式按其置信度顺序返回。
工具状态:
“工具状态”返回有关工具状态的信息,因此可用于处理错误。请参阅主题工具状态结果,了解关于不同工具状态结果的更多信息。
其他结果
边界框的轮廓:
此结果将检测到的对象的边界框作为轮廓返回。
对象实例:
该结果返回检测到的对象实例的区域。返回的值按置信度排序。
只有在使用深度学习模型进行实例分割时,才能确定区域。如果使用对象检测模型,则该结果为空。
X 轴:
此结果包含所有检测到的对象的边界框中心点的 X 轴 坐标。它们以像素为单位,并以元组的形式按其置信度顺序返回。它包含与“对象数量”结果的值相同数量的 X 轴 坐标。
Y 轴:
此结果包含所有检测到的对象的边界框中心点的 Y 轴 坐标。它们以像素为单位,并以元组的形式按其置信度顺序返回。它包含与“对象数量”结果的值相同数量的 Y 轴 坐标。
角度:
此结果返回检测到的对象边界框的角度。它们确定边界框的旋转度和旋转方向。角度以实数(单位为度)和元组的形式按置信度顺序返回。元组包含与“对象数量”结果的值相同数量的角度。
|
值 |
描述 |
|---|---|
|
0 |
矩形未旋转。 |
|
1 至 180 |
矩形沿逆时针方向旋转。 |
|
-1 至 -180 |
矩形沿顺时针方向旋转。 |
当使用为定向对象检测而训练的模型文件时,该结果只返回 -180° 到 180° 之间的角度。如果模型文件是用只支持轴平行边界框的深度学习方法训练的,那么生成的元组中的所有值都将是 0.0。
使用的处理单元:
此结果返回上次迭代中使用的处理单元。如果参数“处理单元”设置为“自动”,可以使用此结果检查实际使用的处理单元,或者检查使用的处理单元是否正确。
精度数据类型:
此结果返回内部用于优化推理深度学习模型的数据类型。您可以使用此结果检查是否使用了正确的精度,以防出现任何问题。
如果参数“精度”设置为“高”,深度学习模型应转换为“float32”的精度。因此,预期此结果返回数据类型“float32”。如果参数“精度”设置为“中等”,深度学习模型应转换为“float16”的精度。在这种情况下,此结果的预期值为数据类型“float16”。如果在 MVApp 迭代过程中出现任何问题,可以检查此结果是否返回与预期不同的数据类型,还可以查看日志文件以了解更多信息。请参阅日志记录主题以了解关于日志文件的更多信息。
处理时间:
此结果返回最近一次执行工具的持续时间(以毫秒为单位)。该结果作为附加结果提供。因此,默认情况下它是隐藏的,但是可以通过工具结果旁边的 ![]() 按钮显示。有关更多信息,处理时间请参工具参考中所阅部分。
按钮显示。有关更多信息,处理时间请参工具参考中所阅部分。
应用程序示例
此工具用于以下 MERLIC Vision App 示例:
- find_and_count_screw_types.mvapp
- segment_pills_by_shape.mvapp

