Ausdruck auswerten
Verwenden Sie dieses Tool, wenn Sie Ausdrücke auswerten möchten, d. h. Ergebnisse der Anwendung überprüfen möchten. Die Ausdrücke können numerische oder Zeichenfolgeergebnisse vorheriger Tools oder manuell eingegebene Werte enthalten. Sie können eine Vielzahl von unterschiedlichen Ausdrücken für die Auswertung verwenden. Eine ausführliche Beschreibung der möglichen Ausdrücke finden Sie im Abschnitt Ausdruck.
Im Gegensatz zu anderen MERLIC-Tools verfügt dieses Tool über keine Standardparameter, wenn es eingefügt wird. Wenn Sie Parameter in Ausdrücken verwenden möchten, müssen Sie diese manuell zum Tool hinzufügen. Weitere Informationen finden Sie im Abschnitt Hinzufügen von Parametern.
Anstelle eines Grafikfensters umfasst dieses Tool Eingabefelder, in denen die Ausdrücke definiert werden können. Die Ergebnisse der ausgewerteten Ausdrücke werden am unteren Rand des Tools ausgegeben. Das Tool verfügt über keine Standardparameter, wenn es eingefügt wird.
Einen Ausdruck eingeben
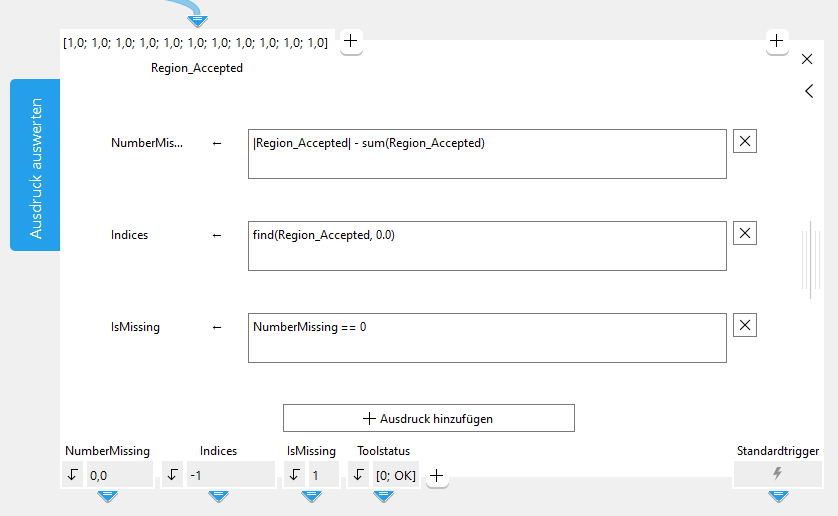
Bei der Eingabe eines Ausdrucks in ein Eingabefeld wird eine automatische Vervollständigungsliste mit möglichen Funktionen und Operatoren für die jeweilige Eingabe eingeblendet. Die Liste enthält auch manuell hinzugefügte Parameter und zuvor definierte Ergebnisse. Sie können also das Ergebnis vorangehender Ausdrücken in diesem Tool in nachfolgenden Ausdrücken in diesem Tool verwenden, z. B. das Ergebnis des ersten Ausdrucks im dritten Ausdruck. Es ist jedoch nicht möglich, das Ergebnis eines späteren Ausdrucks in einem früheren Ausdruck zu verwenden, z. B. das Ergebnis des dritten Ausdrucks im ersten Ausdruck.
Sie können die gesamte Liste direkt manuell über die Tastenkombination STRG+Leertaste aufrufen und durchsuchen. Weitere Informationen zu den möglichen Funktionen und Operatoren finden Sie im Abschnitt Operationstypen.
Die folgende Abbildung zeigt die Popup-Liste mit sämtlichen möglichen Funktionen und Operatoren, nachdem sie manuell über STRG+Leertaste geöffnet wurde. Am Anfang der Liste sehen Sie das Ergebnis des ersten Ausdrucks, „NumberMissing“, und den Parameter „Region_Accepted“.
Ausdrücke hinzufügen, entfernen und verschieben
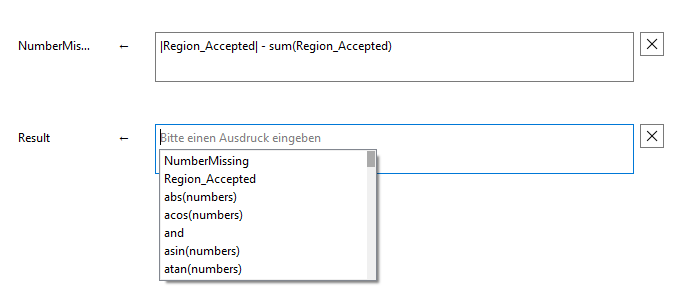
Sie können manuell weitere Ausdrücke hinzufügen sowie Ausdrücke entfernen. Um einen Ausdruck hinzuzufügen, klicken Sie auf die Schaltfläche „![]() Ausdruck hinzufügen“ unten im Tool-Arbeitsbereich. Sie können einen Ausdruck entfernen, indem Sie auf die Schaltfläche
Ausdruck hinzufügen“ unten im Tool-Arbeitsbereich. Sie können einen Ausdruck entfernen, indem Sie auf die Schaltfläche ![]() rechts neben dem Eingabefeld klicken.
rechts neben dem Eingabefeld klicken.
Alternativ können Sie unten im Tool-Arbeitsbereich mit der rechten Maustaste auf das Ergebnis klicken und „Entfernen“ auswählen, um das Ergebnis und den jeweiligen Ausdruck zu entfernen.
Sie können Ziehen und Ablegen verwenden, um die hinzugefügten Ausdrücke zu verschieben und die Reihenfolge der Ausdrücke zu ändern, damit Sie beispielsweise das Ergebnis eines vorherigen Ausdrucks in einem nachfolgenden Ausdruck verwenden können. Wählen Sie dazu den Ausdruck aus, den Sie verschieben möchten, ziehen Sie ihn an die gewünschte Position, und legen Sie ihn an der neuen Stelle ab.
Für jeden neuen Ausdruck wird ein Ergebnis erstellt und am unteren Rand des Tools ausgegeben. Sie können das Ergebnis umbenennen, indem Sie auf den Ergebnisnamen am unteren Rand des Tools doppelklicken. Weitere Informationen zu den zulässigen Namenskonventionen für Toolparameter und -ergebnisse finden Sie unter Tools und Verbindungsstellen umbenennen.
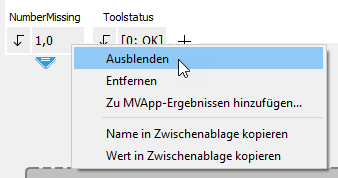
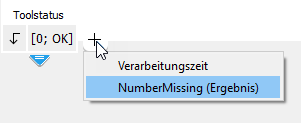
Sie können Ergebnisse auch ausblenden, beispielsweise wenn es Zwischenergebnisse gibt, die mit keinem anderen Tool verbunden sind und lediglich in einem nachfolgenden Ausdruck im Tool-Flow verwendet werden. Klicken Sie mit der rechten Maustaste auf das Ergebnis, das Sie ausblenden möchten, und wählen Sie „Ausblenden“ aus. Klicken Sie auf die Schaltfläche ![]() rechts neben den Ergebnissen, um ein ausgeblendetes Ergebnis anzuzeigen.
rechts neben den Ergebnissen, um ein ausgeblendetes Ergebnis anzuzeigen.
Parameter
Dieses Tool verfügt über keine Parameter. Daher werden beim Einfügen des Tools keine Parameter angezeigt. Wenn Sie einen Parameterwert im Ausdruck verwenden möchten, können Sie den Ergebniswert eines vorherigen Tools verwenden oder einen neuen Parameter für das Tool definieren.
Unterstützte semantische Typen
Dieses Tool unterstützt die folgenden semantischen Typen für die Parameter:
- beliebig
- double
- long
- string
Obwohl nicht alle in MERLIC verfügbaren semantischen Typen für dieses Tool unterstützt werden, können Sie weiterhin ein beliebiges numerisches Ergebnis oder Zeichenfolgeergebnis eines vorherigen Tools verwenden – auch dann, wenn der semantische Typ des betreffenden Ergebnisses nicht unterstützt wird, z. B. „Toolstatus“. Wird jedoch eine Verbindung zu einem solchen Ergebnis erstellt, wird der semantische Typ des jeweiligen neuen Parameters konvertiert und auf „beliebig“ festgelegt.
Da der semantische Typ „long“ Ganzzahlen mit einem größeren Wertebereich darstellt, wird in der folgenden Beschreibung der Begriff „Ganzzahl“ verwendet.
Parameter hinzufügen
Ergebnis eines vorherigen Tools als Parameter verwenden
Um das Ergebnis eines vorherigen Tools im Ausdruck zu verwenden, müssen Sie das Ergebnis mit dem Tool „Ausdruck auswerten“ verbinden.
- Wechseln Sie zum vorherigen Tool, dessen Ergebnis Sie als Parameter im Tool „Ausdruck auswerten“ verwenden möchten.
- Ziehen Sie den Pfeil der Verbindung vom gewünschten Toolergebnis an die gewünschte Verbindungsstelle. Alternativ können Sie das Kontextmenü öffnen und den entsprechenden Menüeintrag „Verbinden zu“ auswählen.
- Wählen Sie das Tool „Ausdruck auswerten“ aus und klicken Sie auf den Menüeintrag „<Verbindung hinzufügen>“.
Das verbundene Ergebnis wird sofort als neuer Parameter für das Tool „Ausdruck auswerten“ hinzugefügt. Name und semantischer Typ des Parameters werden automatisch vom verbundenen Ergebnis übernommen. Wird der semantische Typ des verbundenen Ergebniswerts in diesem Tool nicht unterstützt, wird er für den neuen Parameter automatisch auf „beliebig“ festgelegt.
Alternativ können Sie auch einem neuen Parameter für das Tool definieren (siehe folgende Beschreibung) und den neuen Parameter mit dem Ergebnis eines vorherigen Tools verbinden.
Neuen Parameter definieren
Um einen neuen Parameter zu definieren, müssen Sie eine neue Verbindungsstelle hinzufügen und die Parametereinstellungen definieren.
- Klicken Sie auf die Schaltfläche
 oben links im Toolboard. Das Dialogfenster zum Definieren von Parametereinstellungen wird geöffnet.
oben links im Toolboard. Das Dialogfenster zum Definieren von Parametereinstellungen wird geöffnet. - Wählen Sie den semantischen Typ für den neuen Parameter im Dialogfenster aus.
- Definieren Sie ggf. den minimalen und maximalen Wert für den neuen Parameter.
- Klicken Sie auf „OK“, um die Einstellungen zu bestätigen. Der neue Parameter wird sofort mit einem Standardnamen hinzugefügt.
- Sie können den Parameter umbenennen, indem Sie auf den Parameternamen doppelklicken. Weitere Informationen zu den zulässigen Namenskonventionen für Toolparameter und -ergebnisse finden Sie im Kapitel Tools und Verbindungsstellen umbenennen.
- Definieren Sie den Wert des hinzugefügten Parameters an der Verbindungsstelle.
Nachdem der semantische Typ und der Wertebereich für einen Parameter gespeichert wurden, können diese Einstellungen nicht mehr geändert werden. Wenn der semantische Typ oder der Wertebereich des Parameters angepasst werden muss, müssen Sie einen anderen neuen Parameter mit den gewünschten Einstellungen hinzufügen.
Beispiel
Das folgende Beispiel veranschaulicht die Verwendung eines Ergebnisses eines vorherigen Tools und eines neu definierten Parameterwerts im Ausdruck.
Ausdrücke
Die Ausdrücke, die ausgewertet werden sollen, müssen im Eingabefeld des Toolboards definiert werden. Wenn noch kein Ausdruck oder ein ungültiger Ausdruck definiert wurde, zeigt MERLIC einen Fehler im Toolboard und im Tool-Flow-Panel an. Dieser Fehler wird jedoch nur angezeigt, weil der Ausdruck fehlt oder falsch ist. Es weist nicht auf einen schwerwiegenden Fehler im Arbeitsbereich hin. Daher gibt das Ergebnis „Toolstatus“ in diesem Fall weiterhin „[0; OK]“ aus.
Die Ausdrücke können auf numerische Werte, Zeichenfolgewerte und auch gemischte Tupel angewendet werden. Um einen Wert eines Toolparameters für die Auswertung zu verwenden, geben Sie den Namen des Parameters in das Eingabefeld des Ausdrucks ein. Es ist auch möglich, einen Ausdruck ohne Parameter zu definieren.
Richtung der Auswertung
Die Auswertung der Ausdrücke erfolgt normalerweise von links nach rechts. Mithilfe von Klammern in den Ausdrücken kann jedoch die Reihenfolge der Auswertung geändert werden.
Operationstypen
Bei der Beschreibung von Operationen wird normalerweise von atomaren Tupeln Bei einem Tupel handelt es sich um eine Liste von Elementen, z. B. numerischen Werten und Zeichenfolgen., d. h. Tupeln der Länge 1, ausgegangen. Enthält das Tupel mehr als ein Element, funktionieren die meisten Operatoren wie folgt:
- Wenn eines der Tupel eine Länge von eins aufweist, werden alle Elemente der anderen Tupel mit dem betreffenden Einzelwert für die ausgewählte Operation kombiniert.
- Wenn beide Tupel eine Länge größer als eins aufweisen, muss die Länge der beiden Tupel identisch sein (andernfalls tritt ein Fehler auf). In diesem Fall wird die ausgewählte Operation auf alle Elemente mit demselben Index angewendet. Die Länge der resultierenden Tupel stimmt mit der Länge der Eingabetupel überein.
- Wenn eines der Tupel die Länge 0 („[]“) aufweist, tritt ein Fehler auf.
Im Folgenden werden die verschiedenen Operationen beschrieben, die in einem Ausdruck verwendet werden können.
Grundlegende Tupeloperationen sind beispielsweise die Auswahl eines Werts oder mehrerer Werte, die Kombination von Tupeln (Verkettung) oder die Ermittlung der Anzahl von Elementen. Die Operationen für Tupel, die Steuerdaten enthalten, sind in der folgenden Tabelle aufgeführt.
|
Operation |
Beschreibung |
|---|---|
|
tuple[index] |
Wählt das tuple-Element mit der angegebenen index-Nummer aus. 0 <= index < |tuple| |
|
tuple[index_1:index_2] |
Wählt tuple-Elemente von Position index_1 bis index_2 aus. |
|
|tuple| |
Ermittelt die Anzahl der Elemente von tuple. |
|
[tuple_1,tuple_2] |
Verkettet tuple_1 und tuple_2. |
|
[integer_1:integer_2] |
Generiert eine Folge von Werten von integer_1 bis integer_2 mit einem Inkrementwert von 1. |
|
[integer_1:integer_2:integer_3] |
Generiert eine Folge von Werten von integer_1 bis integer_3 mit einem Inkrementwert von integer_2. |
|
find(tuple_1,tuple_2) |
Ermittelt die Indizes aller Vorkommen von tuple_2 in tuple_1 (Rückgabe von -1, wenn keine Übereinstimmung gefunden wird). |
|
gen_tuple_const(length,value) |
Generiert ein neues Tupel mit der vordefinierten Länge length, in dem jedes Element den gleichen Wert aufweist. Die Länge muss als ganze Zahl angegeben werden. |
|
remove(tuple,index) |
Entfernt Elemente mit der angegebenen index-Nummer aus tuple. |
|
select_mask(tuple_1,tuple_2) |
Wählt alle Elemente von tuple_1 aus, für die der entsprechende Maskenwert in tuple_2 größer 0 ist. |
|
subset(tuple,index) |
Wählt tuple-Elemente mit der angegebenen index-Nummer aus. Sie können eine einzige Indexnummer oder ein Tupel von Indizes angeben. |
|
uniq(tuple) |
Löscht alle aufeinander folgenden, identischen Elemente bis auf ein Element aus tuple. |
Die Verkettung akzeptiert eine oder mehrere Variablen oder Konstanten als Eingabe. Sie werden alle zwischen den Klammern mit Kommas als Trennzeichen aufgelistet. Das Ergebnis ist wiederum ein Tupel. Bitte beachten Sie Folgendes: [[tuple]] = [tuple] = tuple.
|tuple| gibt die Anzahl der Elemente eines Tupels zurück. Die Indizes der Elemente reichen von null bis zur Anzahl der Elemente minus eins, d. h. |tuple|−1. Der Auswahlindex muss daher in diesem Bereich liegen.
|
Beispieltupel |
Beispieloperation |
|---|---|
|
tuple = [7,8,9] |
tuple[1] = 8 |
|
tuple = [1,2,3,7,8,9] |
tuple[2:4] = [3;7;8] |
|
tuple = [7,8,9] |
|tuple| = 3 |
|
tuple_1 = [1,2,3] tuple_2 = [7,8,9] |
[0,tuple_1,tuple_2,27,89] = [0;1;2;3;7;8;9;27;89] |
|
integer_1 = 7 integer_2 = 13 |
[integer_1:integer_2] = [7;8;9;10;11;12;13] |
|
integer_1 = 1 integer_2 = 2 integer_3 = 10 |
[integer_1:integer_2:integer_3] = [1;3;5;7;9] |
|
tuple_1 = [1,2,3,7,8,9] tuple_2 = [3,7] tuple_3 = [7,3] |
find(tuple_1, tuple_2) = 2 find(tuple_1, tuple_3) = -1 |
|
length = 4 value = 23 |
gen_tuple_const(4,23) = [23;23;23;23] |
|
tuple = [1,2,3,7,8,9] |
remove(tuple, [0,4]) = [2;3;7;9] |
|
tuple_1 = [0,1,2,3,4,5] tuple_2 = [1,1,0,1,0,0] |
select_mask(tuple_1, tuple_2) = [0;1;3] |
|
tuple = [2,4,8,16,16,32] |
subset(tuple, [0,2,4]) = [2;8;16] |
|
tuple = [1,1,0,1,0,0] |
uniq(tuple) = [1;0;1;0] |
Die folgenden grundlegenden arithmetischen Operationen sind verfügbar.
|
Operation |
Beschreibung |
|---|---|
|
number_1 / number_2 |
Division |
|
number_1 * number_2 |
Multiplikation |
|
number_1 % number_2 |
Modulus |
|
number_1 + number_2 |
Addition |
|
number_1 - number_2 |
Subtraktion |
|
-number_1 |
Negation |
Modulus kann nur auf ganze Zahlen angewendet werden. Alle anderen Operationen können auf ganze Zahlen oder reelle Zahlen angewendet werden. Ist mindestens einer der Operanden eine reelle Zahl, ist auch das Ergebnis eine reelle Zahl.
Beispiele für arithmetische Operationen
|
Ausdruck |
Ergebnis |
|---|---|
|
4 / 3 |
1 |
|
4 / 3.0 |
1.3333333 |
|
(4 / 3) * 2.0 |
2.0 |
Für die bitweise Verarbeitung von Zahlen stehen die folgenden Operationen zur Verfügung. Die Operanden müssen Ganzzahlen sein.
|
Operation |
Beschreibung |
|---|---|
|
lsh (integer_1,integer_2) |
Verschiebung nach links. Das Ergebnis ist eine bitweise Verschiebung nach links von integer_1, die integer_2 Mal angewendet wird. |
|
rsh (integer_1,integer_2) |
Verschiebung nach rechts. Das Ergebnis ist eine bitweise Verschiebung nach rechts von integer_1, die integer_2 Mal angewendet wird. |
|
integer_1 band integer_2 |
Bitweises „und“ |
|
integer_1 bxor integer_2 |
Bitweises „xor“ |
|
integer_1 bor integer_2 |
Bitweises „oder“ |
|
bnot integer |
Bitweises Komplement |
Bei den Operationen lsh und rsh ist das Ergebnis unbestimmt, wenn der zweite Operand einen negativen Wert aufweist oder der Wert größer als 32 ist.
Es stehen mehrere Zeichenfolgeoperationen zur Verfügung, um Zeichenfolgen zu modifizieren, auszuwählen und zu kombinieren. Darüber hinaus gibt es einige Operationen, mit denen Ganzzahlen und reelle Zahlen in Zeichenfolgen umgewandelt werden können.
|
Operation |
Beschreibung |
|---|---|
|
value $ string |
Wandelt value mit der Spezifikation string um. Weitere Informationen finden Sie im Abschnitt $ (Zeichenfolgeumwandlung). |
|
value_1 + value_2 |
Verkettet value_1 und value_2. Mindestens einer der Werte muss eine Zeichenfolge sein. |
|
strchr(string, char) |
Sucht das erste Vorkommen eines Zeichens aus char in string. |
|
strrchr(string, char) |
Sucht das letzte Vorkommen eines Zeichens aus char in string (von rechts). |
|
strstr(string_1, string_2) |
Sucht das erste Vorkommen der Teilzeichenfolge string_2 in string_1. |
|
strrstr(string_1, string_2) |
Sucht das letzte Vorkommen der Teilzeichenfolge string_2 in string_1 (von rechts). |
|
strlen(string) |
Gibt die Länge von string zurück. |
|
string{index} |
Wählt das Zeichen an der Position index aus. 0 <= index <= strlen(string)-1. |
|
string{index_1:index2} |
Wählt die Teilzeichenfolge von Position index_1 bis Position index_2 aus. |
|
split(string_1, string_2) |
Teilt string_1 bei string_2 in zwei Teilzeichenfolgen auf. |
|
regexp_match(string_1, string_2) |
Extrahiert die Teilzeichenfolgen von string_1, die dem regulären Ausdruck string_2 entsprechen. |
|
regexp_replace(string_1, regex, string_2) |
Ersetzt die erste Teilzeichenfolge von string_1, die dem regulären Ausdruck regex entspricht, durchstring_2. |
|
regexp_select(string, regex) |
Wählt Tupelelemente von string aus, die dem regulären Ausdruck regex entsprechen. |
|
regexp_test(string, regex) |
Gibt die Anzahl der Tupelelemente in string zurück, die dem regulären Ausdruck regex entsprechen. |
|
Beispielzeichenfolge |
Beispieloperation |
|---|---|
|
string = '0,7f' |
4 $ 'string' = "4.0000000" |
|
value_1 = 'good' value_2 = 'morning' |
value_1 + value_2 = 'goodmorning' |
|
string = 'exemplary' |
strchr(string, 'xyz') = 1 |
|
string = 'exemplary' |
strrchr(string, 'xyz') = 8 |
|
string_1 = 'mississippi' string_2 = 'ss' |
strstr(string_1, string2) = 2 |
|
string_1 = 'mississippi' string_2 = 'ss' |
strrstr(string_1, string2) = 5 |
|
string = 'incomprehensibilities' |
strlen(string) = 21 |
|
string = 'abaaabbaababaa' |
string{7} = "a" |
|
string = 'abaaabbaababaa' |
string{7:10} = "aaba" |
|
string_1 = 'appendix.pdf' string_2 = '.' |
split(string_1, string_2) = [appendix;pdf] or split(string_1, 'pp') = [a;endix.;df] |
|
string_1 = ['XXS001.JPG', 'XXS002.JPG', 'XXS003.JPG'] string_2 = 'XXS(.*)' |
regexp_match(string_1, string_2) = [001.JPG, 002.JPG, 003.JPG] |
|
string_1 = 'goodmorning' regex = 'g' string_2 = 'G' |
regexp_replace(string_1, regex, string_2) = "Goodmorning" |
|
string = ['img1.jpg', 'img2.png'; 'appendix.pdf', my_dir'] regex = '.(jpg|png)' |
regexp_select(string, regex) = ['img1.jpg', 'img2.png'] |
|
string = ['img1.jpg', 'img1.png', 'img2.jpg', 'img2.png'] regex = '(.png)' |
regexp_test(string, regex) = 2 |
Weitere Informationen finden Sie in der ausführlicheren Beschreibung der jeweiligen Zeichenfolgeoperation.
$ ermöglicht die Umwandlung von Zahlen in Zeichenfolgen oder die Modifikation von Zeichenfolgen. Der Operand auf der linken Seite von $ ist die Zahl, die umgewandelt wird. Der Operand auf der rechten Seite von $ legt die Art der Umwandlung fest. Dieser ist mit der Formatzeichenfolge der printf()-Funktion in der Programmiersprache C vergleichbar. Die Formatzeichenfolge besteht aus den folgenden vier Teilen:
<Flags><Breite>.<Genauigkeit><Umwandlung>
Als regulärer Ausdruck:
[-+ #]?([0-9]+)?(\.[0-9]*)?[doxXfeEgGsb]?
Der reguläre Ausdruck steht für eine Zeichenfolge, die aus null oder mehr Zeichen im ersten Klammernpaar, gefolgt von null oder mehr Ziffern, hinter denen ein Punkt stehen kann, hinter dem wiederum Ziffern und ein Umwandlungszeichen aus dem letzten Klammernpaar stehen kann.
Beispiele für die Umwandlung von Zeichenfolgen mit $
|
Ausdruck |
Ergebnis |
|---|---|
|
23 $ '10.2f' |
"23.00" → ".....23.00" |
|
23 $ '-10.2f' |
"23.0 " → "23.00....." |
|
4 $ '.7f' |
"4.0000000" |
|
1234.56789 $ '+10.3f' |
" +1234.568" |
|
255 $ 'x' |
"ff" |
|
255 $ 'X' |
"FF" |
|
0xff $ '.5d' |
"00255" |
|
'total' $ '10s' |
"total" → ".....total" |
|
'total' $ '-10s' |
"total " → "total....." |
|
'total' $ '10.3' |
"tot"→ ".......tot" |
Zum besseren Verständnis sind die Ergebnisse mit zusätzlichen Leerzeichen ein zweites Mal aufgelistet, wobei Punkte die zusätzlichen Leerzeichen vor und hinter der Eingabezeichenfolge darstellen. In der Zeichenfolge „total.....“ stehen die letzten 5 Punkte beispielsweise für Leerzeichen.
Die einzelnen Teile der Formatzeichenfolge sind wie folgt definiert:
Flags:
Null oder mehr Flags in beliebiger Reihenfolge, die die Bedeutung der Umwandlungsspezifikation festlegen. Flags können die folgenden Zeichen umfassen:
Flag
Beschreibung
-
Das Ergebnis der Umwandlung ist im Feld links ausgerichtet.
+
Das Ergebnis einer vorzeichenbehafteten Umwandlung beginnt immer mit einem Vorzeichen, d. h. + oder -.
Leerzeichen
Wenn das erste Zeichen einer vorzeichenbehafteten Umwandlung kein Vorzeichen ist, wird dem Ergebnis ein Vorzeichen vorangestellt.
#
Der Wert muss in eine „alternative Form“ umgewandelt werden.
Bei d- und s-Umwandlungen (siehe unten) hat dieses Flag keine Auswirkung.
Bei einer o-Umwandlung (siehe unten) wird die Genauigkeit erhöht, damit die erste Ziffer des Ergebnisses eine Null ist.
Bei x- oder X-Umwandlungen (siehe unten) wird einem von null verschiedenen Ergebnis 0x bzw. 0X vorangestellt.
Bei e-, E-, f-, g- und G-Umwandlungen enthält das Ergebnis immer ein Radixzeichen (auch dann, wenn hinter dem Radixzeichen keine Ziffern stehen).
Bei g- und G-Umwandlungen werden führende Nullen nicht aus dem Ergebnis entfernt (entgegengesetzt zum üblichen Verhalten).
Breite:
Eine optionale Zeichenfolge aus Dezimalziffern zum Angeben einer minimalen Feldbreite. Wenn der umgewandelte Wert bei einem Ausgabefeld weniger Zeichen umfasst als die Feldbreite, wird der Wert auf der linken Seite bis zur Feldbreite aufgefüllt (bzw. auf der rechten Seite, falls das Linksausrichtungsflag - angegeben wurde).
Genauigkeit:
Die Genauigkeit gibt die minimale Anzahl der anzuzeigenden Ziffern für Ganzzahlenumwandlungen (das Feld wird mit führenden Nullen aufgefüllt), die Anzahl der anzuzeigenden Ziffern hinter dem Radixzeichen bei e- und f-Umwandlungen, die maximale Anzahl signifikanter Ziffern bei g-Umwandlungen bzw. die maximale Anzahl auszugebender Zeichen bei einer Zeichenfolgenumwandlung an. Die Angabe der Genauigkeit erfolgt in Form eines Punkts . mit einer Dezimalziffernzeichenfolge dahinter. Eine leere Ziffernzeichenfolge wird als Null behandelt.
Umwandlung:
Die Art der gewünschten Umwandlung wird durch ein Umwandlungszeichen angegeben:
Umwandlungszeichen
Beschreibung
d, o, x, X
Das ganzzahlige Argument wird in vorzeichenbehafteter Dezimal- (d), vorzeichenloser Oktal- (o) oder vorzeichenloser Hexadezimalschreibweise (x und X) ausgegeben.
Bei der x-Umwandlung werden die Zahlen und Kleinbuchstaben 0123456789abcdef, bei der X-Umwandlung die Zahlen und Großbuchstaben 0123456789ABCDEF verwendet. Die Genauigkeitskomponente des Arguments bestimmt die minimale Anzahl anzuzeigender Ziffern.
Wenn der umgewandelte Wert mit weniger Ziffern als das angegebene Minimum dargestellt werden kann, wird er mit führenden Nullen erweitert. Die Standardgenauigkeit ist 1. Bei der Umwandlung eines Nullwerts mit einer Genauigkeit von 0 werden keine Zeichen zurückgegeben.
f
Das Fließkommazahlenargument wird in Dezimalschreibweise in der Form [-]ddd.ddd ausgegeben, wobei die Anzahl der Ziffern hinter dem Radixzeichen, ., der angegebenen Genauigkeit entspricht.
Wird im Argument keine Genauigkeit angegeben, werden sechs Ziffern ausgegeben. Wird die Genauigkeit explizit als 0 angegeben, wird kein Radixzeichen angezeigt.
e, E
Das Fließkommazahlenargument wird in der Form [-]d.ddde+dd ausgegeben, wobei eine Ziffer vor dem Radixzeichen steht und die Anzahl der Ziffern dahinter der angegebenen Genauigkeit entspricht.
Wird keine Genauigkeit angegeben, werden sechs Ziffern ausgegeben. Wird die Genauigkeit als 0 angegeben, wird kein Radixzeichen angezeigt.
Das E-Umwandlungszeichen bewirkt, dass eine Zahl entsteht, bei der E anstelle von e vor dem Exponenten steht. Der Exponent enthält immer mindestens zwei Ziffern. Wenn der auszugebende Wert jedoch einen Exponenten mit mehr als zwei Ziffern notwendig macht, werden bei Bedarf weitere Ziffern im Exponenten ausgegeben.
g, G
Das Fließkommazahlenargument wird in f- oder e-Form (bzw. E-Form, wenn G als Umwandlungszeichen verwendet wird) ausgegeben, wobei die Genauigkeit die Anzahl signifikanter Ziffern angibt.
Die verwendete Form hängt vom umgewandelten Wert ab. Die e-Form wird nur verwendet, wenn der resultierende Exponent der Umwandlung kleiner als -4 bzw. größer-gleich der Genauigkeit ist. Führende Nullen werden aus dem Ergebnis entfernt. Ein Radixzeichen wird nur angezeigt, wenn dahinter eine Ziffer folgt.
s
Das Argument wird als Zeichenfolge verarbeitet. Die Zeichen der Zeichenfolge werden ausgegeben, bis das Ende der Zeichenfolge oder die Anzahl der Zeichen erreicht ist, die durch die Genauigkeit des Arguments bestimmt wird.
Wird keine Genauigkeit im Argument angegeben, wird sie als unendlich interpretiert, sodass alle Zeichen bis zum Ende der Zeichenfolge ausgegeben werden.
Eine nicht vorhandene oder unzureichende Feldgröße bewirkt in keinem Fall, dass ein Feld abgeschnitten wird. Wenn das Ergebnis einer Umwandlung breiter ist als die Feldbreite, wird das Feld einfach dem Umwandlungsergebnis entsprechend erweitert.
Die Zeichenfolgenverkettung (+) kann zusammen mit Zeichenfolgen sowie allen numerischen Typen angewendet werden. Die Operanden werden bei Bedarf zuerst in Zeichenfolgen umgewandelt (gemäß der jeweiligen Standarddarstellung). Mindestens ein Operand muss bereits eine Zeichenfolge sein, damit der Operator für die Zeichenfolgenverkettung verwendet werden kann.
Beispiel für eine Zeichenfolgenverkettung
|
Ausdruck |
Ergebnis |
|---|---|
|
'Name'+Counter+'.png' |
z. B. „Name2.png“ |
In diesem Beispiel wird ein Dateiname erstellt (z. B. „Name2.png“). Dazu werden zwei Zeichenfolgekonstanten („Name“ und „.png“) und ein Ganzzahlenwert (der Schleifenindexzähler) verkettet.
strchr(string,char) gibt den Index des ersten Vorkommens eines der Zeichen in char in der Zeichenfolge string zurück, strrchr(string,char) den Index des letzten Vorkommens eines der Zeichen in char in der Zeichenfolge string. Ist keines der Zeichen in string enthalten, wird -1 zurückgegeben. Bei string kann es sich um eine einzelne Zeichenfolge oder ein Tupel handeln.
Beispiele für str(r)chr
|
Ausdruck |
Ergebnis |
|---|---|
|
strchr('abaaab','a') |
0 |
|
strrchr('abaaab','a') |
4 |
strstr(string_1,string_2) gibt den Index des ersten Vorkommens von string_2 in string_1 zurück und strrstr(string_1,string_2) gibt den Index des letzten Vorkommens von string_2 in string_1 zurück. Ist string_2 nicht in string_1 enthalten, wird -1 zurückgegeben. Bei string_1 kann es sich um eine einzelne Zeichenfolge oder ein Tupel handeln.
Beispiele für str(r)str
|
Ausdruck |
Ergebnis |
|---|---|
|
strstr('abaaab','ab') |
0 |
|
strrstr('abaaab','ab') |
4 |
strlen(string) gibt die Anzahl der Zeichen in string zurück.
Beispiel für strlen
|
Ausdruck |
Ergebnis |
|---|---|
|
strlen('abaaab') |
6 |
string{index} wählt ein einzelnes Zeichen in string aus, das über die Indexposition bestimmt wird. Der Index reicht von null bis zur Länge von string minus 1. Das Ergebnis des Operators ist eine Zeichenfolge der Länge eins.
string{index_1:index_2} gibt alle Zeichen von der ersten angegebenen Indexposition (index_1) bis zur zweiten angegebenen Position (index_2) in s als Zeichenfolge zurück. Der Index reicht von null bis zur Länge von string minus 1.
Beispiele für {}
|
Ausdruck |
Ergebnis |
|---|---|
|
'abaaab'{1} |
"b" |
|
'abaaab'{1:5} |
"baab" |
split(string_1,string_2) unterteilt string_1 in einzelne Teilzeichenfolgen. String_1 wird an den Positionen aufgeteilt, an denen ein Zeichen aus string_2 steht.
Beispiel für split
|
Ausdruck |
Ergebnis |
|---|---|
|
split('/usr/image:/usr/proj/image',':') |
["/usr/image";"/usr/proj/image"] |
Die Zeichenfolge wird am Zeichen „:“ in zwei Teilzeichenfolgen aufgeteilt. Die Teilzeichenfolgen werden in einem Tupel zurückgegeben.
regexp_match(string_1,string_2) sucht Elemente des Tupels string_1, die dem regulären Ausdruck string_2 entsprechen. Es wird ein Tupel mit derselben Größe wie das Eingabetupel zurückgegeben. Das resultierende Tupel enthält die übereinstimmenden Ergebnisse für jedes Tupelelement des Eingabetupels. Bei einer Übereinstimmung wird die entsprechende Teilzeichenfolge zurückgegeben. Andernfalls wird eine leere Zeichenfolge zurückgegeben.
Beispiele für regexp_match
|
Ausdruck |
Ergebnis |
|---|---|
|
regexp_match('abba','b+a*') |
"bba" |
|
regexp_match(['img123','img124'],'img(.*)') |
["123";"124"] |
regexp_replace(string_1,regex,string_2) ersetzt die Teilzeichenfolgen in string_1, die dem regulären Ausdruck regex entsprechen, durch die in string_2angegebene Zeichenfolge. Standardmäßig wird nur die erste übereinstimmende Teilzeichenfolge der einzelnen Elemente in string_1 ersetzt. Wenn alle Vorkommen ersetzt werden sollen, muss die Option 'replace_all' in regex festgelegt werden.
Beispiele für regexp_replace
|
Ausdruck |
Ergebnis |
|---|---|
|
regexp_replace('abaaab','a','b') |
"bbaaab" |
|
regexp_replace('abaaab',['a','replace_all'],'b') |
"bbbbbb" |
regexp_select(string_1,regex) gibt nur die Elemente des Tupels string_1 zurück, die dem regulären Ausdruck regex entsprechen. Im Gegensatz zu regexp_match werden die ursprünglichen Tupelelemente anstelle der übereinstimmenden Teilzeichenfolgen zurückgegeben. Tupelelemente, die nicht dem regulären Ausdruck entsprechen, werden gelöscht. Darüber hinaus unterstützt regexp_select die Option 'invert_match'. Diese Option bewirkt, dass die Eingabezeichenfolgen ausgewählt werden, die nicht dem regulären Ausdruck entsprechen.
Beispiele für regexp_select
|
Ausdruck |
Ergebnis |
|---|---|
|
regexp_select(['mydir', 'a.png', 'b.txt', 'c.bmp', 'd.dat'], '.(bmp|png)') |
["a.png"; "c.bmp"] |
|
regexp_select(['mydir', 'a.png', 'b.txt', 'c.bmp', 'd.dat'], ['.(bmp|png)', 'invert_match']) |
["mydir"; "b.txt"; "d.dat"] |
regexp_test(string,regex) gibt die Anzahl der Elemente des Tupels string zurück, die dem regulären Ausdruck regex entsprechen. Darüber hinaus gibt es eine Kurzschreibweise des Operators, die in Bedingungsausdrücken praktisch ist: string_1 =~ string_2
|
Ausdruck |
Ergebnis |
|---|---|
|
regexp_test(['mydir','a.png','b.txt','c.bmp','d.dat'],'.(bmp|png)') |
2 |
|
['mydir','a.png','b.txt','c.bmp','d.dat'] =~ '.(bmp|png)' |
2 |
Die folgenden Vergleichsoperationen können ausgewertet werden. Sie sind ebenfalls für Tupel mit einer beliebigen Anzahl von Elementen definiert. Es werden immer boolesche Werte zurückgegeben.
|
Operation |
Beschreibung |
|---|---|
|
tuple_1 < tuple_2 |
Kleiner als |
|
tuple_1 > tuple_2 |
Größer als |
|
tuple_1 <= tuple_2 |
Kleiner oder gleich |
|
tuple_1 >= tuple_2 |
Größer oder gleich |
|
tuple_1 == tuple_2 ; tuple_1 = tuple_2 |
Gleich |
|
tuple_1 != tuple_2 ; tuple_1 # tuple_2 |
Ungleich |
tuple_1 == tuple_2 und tuple_1 != tuple_2 sind für alle Typen definiert. Zwei Tupel sind gleich (Rückgabe von „wahr“), wenn sie dieselbe Länge aufweisen und alle Dateneinträge an jeder Indexposition identisch sind. Weisen die Operanden verschiedene Typen auf (ganzzahlig und reell), werden die ganzzahligen Werte zuerst in reelle Zahlen transformiert. Zeichenfolgewerte können nicht zusammen mit Zahlen verwendet werden, d. h., Zeichenfolgewerte können nicht mit Werten anderer Typen verglichen werden.
Beispiele für den Vergleich von Tupeln
|
1. Operand |
Operation |
2. Operand |
Ergebnis |
|---|---|---|---|
|
1 |
== |
1.0 |
1 |
|
[] |
== |
[] |
1 |
|
'' |
== |
[] |
0 |
|
[1,'2'] |
== |
[1,2] |
0 |
|
[1,2,3] |
== |
[1,2] |
0 |
|
[4711,'Hugo'] |
== |
[4711,'Hugo'] |
1 |
|
'Hugo' |
== |
'hugo' |
0 |
|
2 |
> |
1 |
1 |
|
2 |
> |
1.0 |
1 |
|
[5,4,1] |
> |
[5,4] |
1 |
|
[2,1] |
> |
[2,0] |
1 |
|
true |
> |
false |
1 |
|
'Hugo' |
< |
'hugo' |
1 |
Die vier Vergleichsoperationen berechnen die lexikographische Reihenfolge von Tupeln. Die Typen müssen an den jeweiligen Indexpositionen identisch sein. Werte vom Typ „integer“, „real“ und „boolean“ werden jedoch automatisch angepasst. Die lexikographische Reihenfolge gilt für Zeichenfolgen. Das boolesche „falsch“ wird als kleiner als das boolesche „wahr“ betrachtet („falsch“ < „wahr“).
Diese Vergleichsoperationen vergleichen die Eingabetupel tuple_1 und tuple_2 elementweise.
|
Operation |
Beschreibung |
|---|---|
|
tuple_1 [<] tuple_2 |
Kleiner als |
|
tuple_1 [>] tuple_2 |
Größer als |
|
tuple_1 [<=] tuple_2 |
Kleiner oder gleich |
|
tuple_1 [>=] tuple_2 |
Größer oder gleich |
|
tuple_1 [==] tuple_2 ; tuple_1 [=] tuple_2 |
Gleich |
|
tuple_1 [!=] tuple_2 ; tuple_1 [#] tuple_2 |
Ungleich |
Weisen beide Tupel dieselbe Länge auf, werden die entsprechenden Elemente beider Tupel verglichen. Andernfalls müssen entweder tuple_1 oder tuple_2 die Länge 1 aufweisen. In diesem Fall wird jedes Element des längeren Tupels mit dem einzigen Element des anderen Tupels verglichen. Als Vorbedingung für den elementweisen Vergleich von Tupeln müssen zwei entsprechende Elemente jeweils beide Zahlen (Ganzzahl oder Fließkommazahl) oder Zeichenfolgen sein.
Beispiele für den elementweisen Vergleich von Tupeln
|
1. Operand |
Operation |
2. Operand |
Ergebnis |
|---|---|---|---|
|
[1,2,3] |
[<] |
[3,2,1] |
[1;0;0] |
|
['a','b','c'] |
[==] |
'b' |
[0;1;0] |
|
['a','b','c'] |
[<] |
['b'] |
[1;0;0] |
Die folgenden booleschen Operationen können ausgewertet werden.
|
Operation |
Beschreibung |
Ergebnis |
|---|---|---|
|
boolean_1 and boolean_2 |
Logical "and" |
1 (wahr), wenn beide Operanden „wahr“ sind. |
|
boolean_1 xor boolean_2 |
Logical "xor" |
1 (wahr), wenn genau einer der beiden Operanden „wahr“ ist. |
|
boolean_1 or boolean_2 |
Logical "or" |
1 (wahr), wenn mindestens einer der beiden Operanden „wahr“ ist. |
|
not boolean |
Negation |
1 (wahr), wenn die Eingabe „falsch“ (0) ist, und „falsch“, wenn die Eingabe „wahr“ ist. |
Die booleschen Operationen and, xor, or und not sind nur für Tupel der Länge 1 definiert.
Die folgenden trigonometrischen Funktionen können ausgewertet werden.
|
Funktion |
Beschreibung |
|---|---|
|
sin(numbers) |
Sinus von numbers |
|
cos(numbers) |
Cosinus von numbers |
|
tan(numbers) |
Tangens von numbers |
|
asin(numbers) |
Arcussinus von numbers im Intervall |
|
acos(numbers) |
Arcuscosinus von numbers im Intervall |
|
atan(numbers) |
Arcustangens von numbers im Intervall |
|
atan2(numbers_1,numbers_2) |
Arcustangens von numbers_1/numbers_2 im Intervall |
|
sinh(numbers) |
Sinus hyperbolicus von numbers |
|
cosh(numbers) |
Cosinus hyperbolicus von numbers |
|
tanh(numbers) |
Tangens hyperbolicus von numbers |




Alle diese Funktionen können für Tupel von Zahlen als Argumente verwendet werden. Die Eingabe kann eine Ganzzahl oder eine reelle Zahl sein. Das Ergebnis ist jedoch immer eine reelle Zahl. Die Funktionen werden auf alle Tupelwerte angewendet. Das resultierende Tupel hat dieselbe Länge wie das Eingabetupel. Bei atan2 müssen die beiden Eingabetupel dieselbe Länge aufweisen. Bei trigonometrischen Funktionen werden Winkel im Bogenmaß angegeben.
Die folgenden Exponentialfunktionen können ausgewertet werden.
|
Funktion |
Beschreibung |
|---|---|
|
exp(numbers) |
Exponentialfunktion |
|
log(numbers) |
Natürlicher Logarithmus ln(numbers), numbers > 0 |
|
log10(numbers) |
Dekadischer Logarithmus log10(numbers), numbers > 0 |
|
pow(numbers_1,numbers_2) |
|
|
ldexp(numbers_1,numbers_2) |
|



Alle diese Funktionen können für Tupel von Zahlen als Argumente verwendet werden. Die Eingabe kann eine Ganzzahl oder eine reelle Zahl sein. Das Ergebnis ist jedoch immer eine reelle Zahl. Die Funktionen werden auf alle Tupelwerte angewendet. Das resultierende Tupel hat dieselbe Länge wie das Eingabetupel. Bei pow und ldexp müssen die beiden Eingabetupel dieselbe Länge aufweisen.
Die folgenden numerischen Funktionen können ausgewertet werden.
|
Funktion |
Beschreibung |
|---|---|
|
abs(numbers) |
Gibt den absoluten Wert zurück. Dieser weist denselben Typ auf wie numbers (ganze Zahl oder reelle Zahl). |
|
ceil(numbers) |
Gibt den kleinsten ganzzahligen Wert zurück, der nicht kleiner ist als numbers. Diese Funktion kann mit ganzen und reellen Zahlen arbeiten. Das Ergebnis ist immer eine reelle Zahl. |
|
cumul(tuple) |
Gibt die kumulativen Summen der entsprechenden tuple-Elemente zurück. Der resultierende Wert ist eine reelle Zahl, wenn mindestens ein Element eine reelle Zahl ist. Sind alle Elemente ganze Zahlen, ist der resultierende Wert ebenfalls eine ganze Zahl. |
|
deg(numbers) |
Wandelt numbers von Bogenmaß in Grad um. Diese Funktion kann mit ganzen und reellen Zahlen arbeiten. Das Ergebnis ist immer eine reelle Zahl. |
|
deviation(tuple) |
Berechnet die Standardabweichung von tuple. Diese Funktion kann mit ganzen und reellen Zahlen arbeiten. Das Ergebnis ist immer eine reelle Zahl. |
|
fabs(numbers) |
Absolutwert von numbers (immer reell). Diese Funktion kann mit ganzen und reellen Zahlen arbeiten. Das Ergebnis ist immer eine reelle Zahl. |
|
floor(numbers) |
Gibt den größten ganzzahligen Wert zurück, der nicht größer ist als numbers. Diese Funktion kann mit ganzen und reellen Zahlen arbeiten. Das Ergebnis ist immer eine reelle Zahl. |
|
fmod(numbers_1, numbers_2) |
Gibt den Bruchteil von numbers_1/numbers_2 mit demselben Vorzeichen wie numbers_1 zurück. Diese Funktion kann mit ganzen und reellen Zahlen arbeiten. Das Ergebnis ist immer eine reelle Zahl. |
|
int(numbers) |
Wandelt die reelle Zahl numbers in eine Ganzzahl ohne die Dezimalstellen um. Wenn numbers bereits eine Ganzzahl ist, wird die Eingabe zurückgegeben. |
|
max(tuple) |
Wählt den größten Wert von tuple aus. Alle Werte müssen jeweils Zeichenfolgen oder ganze/reelle Zahlen sein. Eine Mischung von Zeichenfolgen mit numerischen Werten ist nicht zulässig. Der resultierende Wert ist eine reelle Zahl, wenn mindestens ein Element eine reelle Zahl ist. Sind alle Elemente ganze Zahlen, ist der resultierende Wert ebenfalls eine ganze Zahl. |
|
max2(tuple_1, tuple_2) |
Wählt das elementweise Maximum von tuple_1 und tuple_2 aus. |
|
mean(tuple) |
Berechnet den Mittelwert von tuple. Diese Funktion kann mit ganzen und reellen Zahlen arbeiten. Das Ergebnis ist immer eine reelle Zahl. |
|
median(tuple) |
Berechnet den Medianwert von tuple. Der resultierende Wert ist eine reelle Zahl, wenn mindestens ein Element eine reelle Zahl ist. Sind alle Elemente ganze Zahlen, ist der resultierende Wert ebenfalls eine ganze Zahl. |
|
min(tuple) |
Wählt den kleinsten Wert von tuple aus. Alle Werte müssen jeweils Zeichenfolgen oder ganze/reelle Zahlen sein. Eine Mischung von Zeichenfolgen mit numerischen Werten ist nicht zulässig. Der resultierende Wert ist eine reelle Zahl, wenn mindestens ein Element eine reelle Zahl ist. Sind alle Elemente ganze Zahlen, ist der resultierende Wert ebenfalls eine ganze Zahl. |
|
min2(tuple_1, tuple_2) |
Wählt das elementweise Minimum von tuple_1 und tuple_2 aus. |
|
rad(numbers) |
Wandelt numbers von Grad in Bogenmaß um. Diese Funktion kann mit ganzen und reellen Zahlen arbeiten. Das Ergebnis ist immer eine reelle Zahl. |
|
real(numbers) |
Wandelt die ganze Zahl numbers in einen reellen Wert um. Wenn numbers bereits ein reeller Wert ist, wird die Eingabe zurückgegeben. |
|
round(numbers) |
Wandelt die reelle Zahl numbers in eine gerundete Ganzzahl um. |
|
select_rank(tuple, index) |
Gibt das Element an der Position index von tuple zurück. Kann für Tupel verwendet werden, die ganzzahlige oder reelle Werte enthalten. index muss eine ganze Zahl sein. |
|
sgn(numbers) |
Vorzeichen eines Werts oder elementweises Vorzeichen eines Tupels. |
|
sqrt(numbers) |
Berechnet die Quadratwurzel von numbers. Diese Funktion kann mit ganzen und reellen Zahlen arbeiten. Das Ergebnis ist immer eine reelle Zahl. |
|
sum(tuple) |
Berechnet die Summe aller tuple-Elemente oder verkettet alle Zeichenfolgen. Alle Werte müssen jeweils Zeichenfolgen oder ganze/reelle Zahlen sein. Eine Mischung von Zeichenfolgen mit numerischen Werten ist nicht zulässig. Der resultierende Wert ist eine reelle Zahl, wenn mindestens ein Element eine reelle Zahl ist. Sind alle Elemente ganze Zahlen, ist der resultierende Wert ebenfalls eine ganze Zahl. Handelt es sich bei den Werten um Zeichenfolgen, wird anstelle der Addition eine Zeichenfolgeverkettung durchgeführt. |
Die folgenden Funktionen können ebenfalls ausgewertet werden:
|
Funktion |
Beschreibung |
|---|---|
|
chr(numbers) |
Wandelt eine ASCII-Zahl in ein Zeichen um. |
|
chrt(integer) |
Wandelt ein Tupel von Ganzzahlen in eine Zeichenfolge um. |
|
environment(string) |
Der Wert einer Umgebungsvariablen. string ist der Name der Umgebungsvariablen als Zeichenfolge. |
|
inverse(tuple) |
Kehrt die Reihenfolge von tuple-Werten um. Wenn tuple leer ist oder die Länge 1 aufweist bzw. tuple in allen Positionen denselben Wert enthält, z. B. [1,1,...,1], sind inverse und sort identisch. |
|
is_number(value) |
Ermittelt, ob value eine Zahl ist. Wenn value eine ganze Zahl, eine reelle Zahl oder eine Zeichenfolge ist, die eine Zahl darstellt, wird 1 (wahr) zurückgegeben. |
|
number(value) |
Wandelt eine Zeichenfolge, die eine Zahl darstellt, abhängig vom jeweiligen Typ der Zahl in eine Ganzzahl oder reelle Zahl um. Zeichenfolgen, die mit „0x“ beginnen, werden als Hexadezimalzahlen, Zeichenfolgen, die mit 0 (null) beginnen, werden als Oktalzahlen interpretiert. Die Zeichenfolge „20“ wird beispielsweise in die Ganzzahl 20, „020“ in 16 und „0x20“ in 32 umgewandelt. Beim Aufruf mit einer Zeichenfolge, die keine Zahl darstellt, oder mit einer Variablen, die eine Ganzzahl oder reelle Zahl ist, gibt „number“ eine Kopie der Eingabe zurück. |
|
ord(numbers) |
ASCII-Zahl eines Zeichens als Ganzzahl. |
|
ords(string) |
Wandelt ein Tupel von Zeichenfolgen in ein Tupel von ASCII-Ganzzahlen um. |
|
rand(numbers) |
Erstellt Zufallszahlen. |
|
sort(tuple) |
Sortiert tuple in aufsteigender Reihenfolge, d. h., der erste Wert des resultierenden Tupels ist der kleinste Wert. Wenn das Tupel leer ist, das Tupel die Länge 1 aufweist oder in allen Positionen denselben Wert enthält, z. B. [1,1,...,1], sind sort und inverse identisch. |
|
sort_index(tuple) |
Sortiert tuple in aufsteigender Reihenfolge, gibt jedoch die Indexpositionen der sortierten Werte zurück. |
Die folgende Tabelle zeigt die Rangfolge der Operationen für Steuerdaten (aufsteigend von oben nach unten). Einige Operationen (z. B. Funktionen, | |, tuple[] usw.) wurden ausgelassen, da deren Argumente offensichtlich sind.
|
Zunehmender Vorrang von oben nach unten |
|---|
|
band |
|
bxor bor |
|
and |
|
xor or |
|
!= == # = |
|
<= >= < > |
|
+ - |
|
/ * % |
|
- (unary minus) not |
|
$ |
Sonderzeichen verwenden
Dieses Tool verwendet einfache Anführungszeichen, um Strings darzustellen. Werden innerhalb der einfachen Anführungszeichen Sonderzeichen verwendet, werden diese mit einem Backslash maskiert. '\t‘ wird beispielsweise als Tabulator behandelt.
Eine Liste der verwendeten Sonderzeichen finden Sie in der folgenden Tabelle.
|
Ersatzausdruck |
Beschreibung |
|---|---|
|
\n |
Zeilenvorschub |
|
\t |
Horizontaler Tabulator |
|
\v |
Vertikaler Tabulator |
|
\b |
Rückschritt |
|
\r |
Wagenrücklauf |
|
\f |
Seitenvorschub |
|
\a |
Tonsignal |
|
\\ |
Backslash |
|
\' |
Einfache Anführungszeichen |
Im folgenden Beispiel sehen Sie die resultierenden Werte, wenn ein Parameter mit Parameter = \t verwendet wird:
|
Ausdruck |
Ergebnis |
Beschreibung |
|---|---|---|
|
Parameter |
\t |
\t wird als Zeichenfolge behandelt. |
|
strlen(Parameter) |
2 |
\t wird als Zeichenfolge mit zwei Zeichen behandelt. |
|
strlen('\t') |
1 |
\twird als Tabulatorzeichen behandelt. |
|
'a\tb' |
a b |
\twird als Tabulator behandelt. |
|
ords(Parameter) |
[92;116] |
\t wird als Zeichenfolge behandelt. |
|
ords('\t') |
9 |
\twird als Tabulatorzeichen behandelt. |
Ergebnisse
Standardergebnisse
Ergebnis:
Dieses Ergebnis gibt die resultierenden Werte des Ausdrucks aus. Standardmäßig ist dies das Ergebnis des ersten Ausdrucks. Jeder weitere Ausdruck gibt ein weiteres Ergebnis aus. Der semantische Typ des Ergebnisses wird auf „beliebig“ festgelegt.
Toolstatus:
„Toolstatus“ gibt Informationen zum Status des Tools aus und kann daher für die Fehlerbehandlung verwendet werden. Weitere Informationen zu den verschiedenen Toolstatus-Ergebnissen finden Sie unter Toolstatus-Ergebnis.
Zusätzliche Ergebnisse
Verarbeitungszeit:
Dieses Ergebnis gibt die Dauer der letzten Ausführung des Tools in Millisekunden aus. Das Ergebnis wird als zusätzliches Ergebnis bereitgestellt. Es ist daher standardmäßig ausgeblendet, kann aber über die Schaltfläche ![]() neben den Toolergebnissen angezeigt werden. Weitere Informationen finden Sie im Abschnitt Verarbeitungszeit in der Tool-Referenz-Übersicht.
neben den Toolergebnissen angezeigt werden. Weitere Informationen finden Sie im Abschnitt Verarbeitungszeit in der Tool-Referenz-Übersicht.
Anwendungsbeispiele
Dieses Tool wird in den folgenden MERLIC-Vision-App-Beispielen verwendet:
- adapt_brightness_for_measuring.mvapp
- calibrate_for_ruler_changed_distance.mvapp
- calibrate_for_ruler_distorted.mvapp
- calibrate_for_ruler_simple.mvapp
- check_bent_leads.mvapp
- check_correct_filling_on_3d_height_images.mvapp
- check_pen_parts.mvapp
- check_presence_of_fuses.mvapp
- check_saw_angles.mvapp
- check_single_switches.mvapp
- classify_pills.mvapp
- count_bottles_with_deep_learning.mvapp
- detect_only_scratches_with_photometric_stereo.mvapp
- determine_circle_quality.mvapp
- evaluate_ecc_200_print_quality.mvapp
- find_and_count_screw_types.mvapp
- measure_distance_segment_circle_calibrated.mvapp
- measure_distance_to_center_led.mvapp
- recognize_color_of_cables.mvapp
- segment_pill_defects.mvapp
- segment_pills_by_shape.mvapp

