Anomalien finden
Mit diesem Tool finden Sie Anomalien in Bildern.
Dieses Tool wird mit einem Trainingsmodus verwendet. Dabei wird zuerst ein Training basierend auf geeigneten Samples von Trainingsbildern mit und ohne Anomalien sowie festgelegten Trainingsparametern durchgeführt. Trainingsbilder mit schlechten Samples, d. h. Bilder mit Anomalien, sind nicht erforderlich, können aber hilfreich sein, um das Deep Learning-Modell zu verbessern.
Das Tool verfügt über einen Trainingsbereich auf der linken Seite des Toolboards. Es bietet die Möglichkeit, zwischen dem Verarbeitungsmodus für die Anomalieerkennung und dem Trainingsmodus zum Trainieren des Deep Learning-Modells zu wechseln. Im Grafikfenster wird das Bild des derzeit aktiven Modus angezeigt, der im Trainingsbereich blau hervorgehoben wird. Zusätzlich zu den Suchparametern oben links stellt das Tool oben rechts im Tool weitere Parameter für das Training bereit.
Weitere Informationen zur Verwendung von Tools, für die ein Training erforderlich ist, finden Sie unter Im Trainingsmodus arbeiten.
Das Toolboard ist in den Trainingsbereich auf der linken Seite der und das Grafikfenster auf der rechten Seite unterteilt.
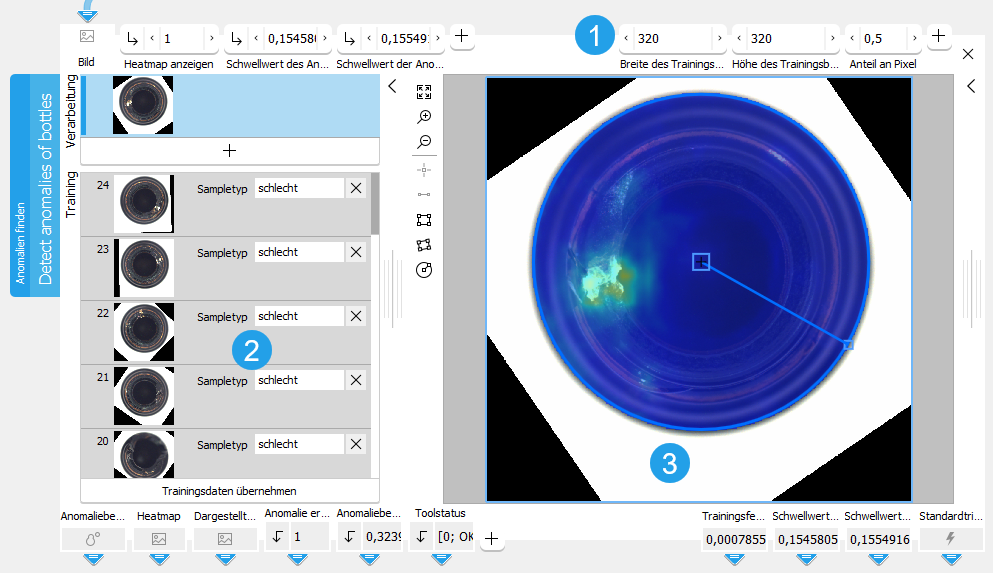
![]() Trainingsparameter
Trainingsparameter
![]() Trainingsbereich
Trainingsbereich
![]() Grafikfenster
Grafikfenster
Angezeigte Bilder
Im Trainingsbereich werden das Verarbeitungsbild und die Trainingsbilder angezeigt.
- Verarbeitungsbild: Das aktuelle „Bild“, das von einem vorherigen Tool stammt.
- Trainingsbilder: Die Bilder, die zum Trainieren des Deep Learning-Modells verwendet werden. Sie können Trainingsbilder mit zwei verschiedenen Sampletypen verwenden: „gut“ für Bilder ohne Anomalien und „schlecht“ für Bilder mit Anomalien.
Training
Trainingsbilder
Zum Trainieren des Modells sind ungefähr 20 bis 100 Bilder ausreichend. Die Trainingsbilder können nur gute Samples, d. h. Bilder ohne Anomalien, umfassen. Trainingsbilder mit schlechten Samples, d. h. Bilder mit Anomalien, können jedoch hilfreich sein, um das Deep Learning-Modell zu verbessern.
Führen Sie die folgenden Schritte aus, um ein Bild als Trainingsbild hinzuzufügen:
- Führen Sie die Anwendung über die Schaltfläche „Einmal ausführen“ oder die Taste F6 in Einzelschritten aus, bis ein Bild angezeigt wird, das Sie als Trainingsbild verwenden möchten.
- Fügen Sie das aktuelle Bild zu den Trainingsbildern hinzu, indem Sie auf die Schaltfläche
 klicken oder die Taste F3 drücken.
klicken oder die Taste F3 drücken. - Legen Sie den gewünschten Sampletyp für jedes Trainingsbild fest („gut“ oder „schlecht“).
- Wiederholen Sie die obigen Schritte, um weitere Trainingsbilder hinzuzufügen.
Training durchführen
Führen Sie die folgenden Schritte aus, um das Training durchzuführen:
- Definieren Sie den Sampletyp für die einzelnen Trainingsbilder:
- „gut“ für Bilder ohne Anomalien
- „schlecht“ für Bilder mit Anomalien
- Passen Sie die Trainingsparameter oben rechts im Tool ggf. an die Trainingsdaten an.
- Klicken Sie auf die Schaltfläche „Trainingsdaten übernehmen“, um das Training durchzuführen.
Nach Durchführung des Trainings wechselt das Tool automatisch in den Verarbeitungsmodus, sodass Sie überprüfen können, ob das trainierte Modell für die Verarbeitungsbilder brauchbar ist oder ob die Suchparameter angepasst werden müssen.
Trainingsdaten prüfen
Die Trainingsparameter werden automatisch an die definierten Trainingsbilder angepasst. Die Suchparameter „Schwellwert des Anomaliebereichs“ und „Schwellwert der Anomaliebewertung“ auf der linken Seite werden beim Training ebenfalls automatisch festgelegt.
Wenn Sie die Anwendung mit mehreren Bildern ausführen, können Sie im Grafikfenster sofort feststellen, ob die Anomalieerkennung mit dem trainierten Deep Learning-Modell ordnungsgemäß funktioniert. Bei Bedarf können Sie weitere Anpassungen an den Trainings- oder Suchparametern vornehmen.
Unterstützung von Artificial Intelligence Acceleration-Schnittstellen (AI²)
MERLIC umfasst Artificial Intelligence Acceleration-Schnittstellen (AI²) für das NVIDIA® TensorRT™ SDK und die Intel® Distribution of OpenVINO™ toolkit. Das heißt, Sie können KI-Beschleuniger-Hardware als Recheneinheit verwenden, die kompatibel mit NVIDIA® TensorRT™ oder dem OpenVINO™ toolkit ist, um optimierte Inferenzberechnungen auf der jeweiligen Hardware durchzuführen, z. B. auf NVIDIA®-GPUs oder Hardware, die das OpenVINO™ toolkit unterstützt, wie CPUs, Intel®-GPUs und Movidius™-VPUs. Dadurch können Sie Deep Learning-Inferenzberechnungen erheblich beschleunigen. Die jeweilige Hardware kann beim Toolparameter „Recheneinheit“ ausgewählt werden.
Voraussetzungen
NVIDIA®-GPUs und CPUs, die das OpenVINO™ toolkit unterstützen, können sofort nach der Installation von MERLIC verwendet werden. Eine zusätzliche Installation oder Einrichtung ist nicht erforderlich.
Für die Verwendung von Intel®-GPUs und VPUs mit dem OpenVINO™ toolkit als Recheneinheit gelten die folgenden Voraussetzungen:
- Zuerst müssen Sie die Intel® Distribution of OpenVINO™ toolkit installieren.
- Sie müssen MERLIC in einer OpenVINO™ toolkit-Umgebung starten.
Weitere Informationen zu Installation und Voraussetzungen finden Sie unter AI²-Schnittstellen für Tools mit Deep Learning.
Parameter
Standardparameter
Bild:
Dieser Parameter stellt das Bild dar, in dem Anomalien gefunden werden sollen.
Heatmap anzeigen:
Dieser Parameter bestimmt, ob die Heatmap angezeigt wird oder nicht. Die Heatmap visualisiert die Anomalien im Bild. Die Standardeinstellung ist 1. Das bedeutet, dass die Heatmap standardmäßig angezeigt wird. Wenn der Parameter auf 0 festgelegt ist, wird keine Heatmap angezeigt. Der Wert dieses Parameters bestimmt auch, ob die Heatmap Bestandteil des Bilds ist, das im Ergebnis „Dargestelltes Bild“ ausgegeben wird.
Zusätzliche Parameter
Verarbeitungsbereich:
Dieser Parameter definiert die Region für die Verarbeitung. Bildteile außerhalb der Vereinigung von ROI und „Verarbeitungsbereich“ werden nicht verarbeitet. Wenn zudem einer der Bereiche leer ist, wird der Bildteil, der innerhalb des jeweils anderen liegt, verarbeitet. Sind beide leer, wird das gesamte Bild verarbeitet.
„Verarbeitungsbereich“ ist standardmäßig als leere Region definiert. Wenn Sie eine „Verarbeitungsbereich“ angeben möchten, müssen Sie den Parameter mit einem geeigneten Ergebnis eines vorherigen Tools verbinden, damit die Region an dieses Tool übertragen wird.
ROI:
Dieser Parameter definiert die ROI für die Verarbeitung. Bildteile außerhalb der Vereinigung von ROI und „Verarbeitungsbereich“ werden nicht verarbeitet. Wenn zudem einer der Bereiche leer ist, wird der Bildteil, der innerhalb des jeweils anderen liegt, verarbeitet. Sind beide leer, wird das gesamte Bild verarbeitet.
Die ROI ist standardmäßig als leere ROI definiert. Wenn Sie eine nicht leere ROI für die Verarbeitung verwenden möchten, müssen Sie den Parameter mit einem geeigneten ROI-Ergebnis eines vorherigen Tools verbinden oder mit den verfügbaren ROI-Schaltflächen neue ROIs zeichnen.
Schwellwert des Anomaliebereichs:
Dieser Parameter definiert, bei welchem Schwellenwert ein Pixel im Bild zu einer Anomalie gehört oder nicht. Der Parameter ist standardmäßig auf 0,5 festgelegt. Der optimale Schwellwert wird im Rahmen des Trainings ermittelt. Wenn der vom Deep Learning-Modell festgelegte Schwellenwert nicht optimal ist, ermöglicht dieser Parameter eine gewisse Feinabstimmung.
Schwellwert der Anomaliebewertung:
Dieser Parameter definiert, bei welchem Schwellenwert das Bild als Bild mit einer Anomalie gezählt wird bzw. wann nicht. Der Parameter ist standardmäßig auf 0,5 festgelegt. Der optimale Schwellwert wird im Rahmen des Trainings ermittelt. Wenn der vom Deep Learning-Modell festgelegte Schwellenwert nicht optimal ist, ermöglicht dieser Parameter eine gewisse Feinabstimmung.
Wenn das Ergebnis „Anomaliebewertung“ größer ist als der im Parameter „Schwellwert der Anomaliebewertung“ festgelegte Wert, wird das Ergebnis „Anomalie erkannt“ auf 1 festgelegt.
Recheneinheit:
Dieser Parameter definiert die Einheit, die für die Verarbeitung der Bilder verwendet wird. Der Parameter ist standardmäßig auf „auto“ festgelegt. In diesem Modus versucht MERLIC, eine geeignete GPU als Recheneinheit auszuwählen, da deren Leistung in der Regel besser ist als die der CPU. Der verfügbare Speicher in der betreffenden GPU muss jedoch mindestens 4 GB groß sein. Wird keine geeignete GPU gefunden, wird ersatzweise die CPU verwendet.
Sie können die Recheneinheit auch manuell auswählen. Klicken Sie auf den Parameter, um die Einheit in der Liste aller verfügbaren Recheneinheiten auszuwählen. Wenn Sie eine GPU als Recheneinheit auswählen, sollten Sie überprüfen, ob genügend Speicher für das verwendete Deep Learning-Modell verfügbar ist. Andernfalls kann es zu unerwünschten Effekten kommen, z. B. langsamere Inferenzberechnungen.
MERLIC unterstützt auch die Verwendung von KI-Beschleuniger-Hardware, die mit dem NVIDIA® TensorRT™ SDK oder dem OpenVINO™ toolkit kompatibel ist:
- NVIDIA®-GPUs
- CPUs, Intel®-GPUs, Intel®-VPUs (MYRIAD und HDDL), die das OpenVINO™ toolkit unterstützen
Die jeweiligen Einheiten werden mit dem Präfix „TensorRT(TM)“ oder „OpenVINO(TM)“ gekennzeichnet. Wenn Sie eine Einheit auswählen, die NVIDIA® TensorRT™ oder das OpenVINO™ toolkit unterstützt, wird der Speicher in der Einheit über das jeweilige Plugin für die AI²-Schnittstelle initialisiert.
Sobald eine KI-Beschleuniger-Hardware als Recheneinheit ausgewählt wurde, wird die Optimierung des Deep Learning-Modells gestartet. Nach der Optimierung werden alle Parameter, die Modellparameter darstellen, intern als schreibgeschützt festgelegt. Die betreffenden Werte können daher nicht mehr geändert werden, solange der ausgewählte KI-Beschleuniger als Recheneinheit verwendet wird. Um die Parameter zu ändern, müssen Sie zuerst eine andere Recheneinheit ohne KI-Beschleunigung auswählen. Nachdem die Parameter festgelegt wurden, können Sie die entsprechende KI-Beschleuniger-Hardware wieder als Recheneinheit verwenden.
CPUs, die das OpenVINO™ toolkit unterstützen, können ohne zusätzliche Installationsschritte verwendet werden. Sie werden automatisch in die Liste der verfügbaren Recheneinheiten aufgenommen. Wenn mehrere Recheneinheiten mit demselben Namen verfügbar sind, wird den Namen eine Indexnummer zugewiesen. Gleiches gilt für GPUs, die NVIDIA® TensorRT™ unterstützen.
Um GPUs und VPUs, die das OpenVINO™ toolkit unterstützen, als Recheneinheit verwenden zu können, muss die Intel® Distribution of OpenVINO™ toolkit auf dem jeweiligen Computer installiert sein. Außerdem muss MERLIC in einer OpenVINO™ toolkit-Umgebung gestartet werden. Ausführlichere Informationen zu den Voraussetzungen finden Sie unter AI²-Schnittstellen für Tools mit Deep Learning.
Neben der Optimierung über KI-Beschleuniger-Hardware unterstützt MERLIC weitere dynamische Optimierungen über das NVIDIA® CUDA® Deep Neural Network (cuDNN). Diese Optimierung kann über die MERLIC-Einstellungen im MERLIC Creator aktiviert werden. Weitere Informationen finden Sie unter MERLIC-Einstellungen.
Präzision:
Dieser Parameter legt den Datentyp fest, der intern für die Optimierung des Deep Learning-Modells für Inferenz verwendet wird, d. h., er legt die Präzision fest, mit der das Modell konvertiert wird. Die Standardeinstellung ist „hoch“.
Die folgende Tabelle zeigt die Einstellungen für die Modellpräzision, die in diesem Tool unterstützt werden.
|
Wert |
Beschreibung |
|---|---|
|
hoch |
Das Deep Learning-Modell wird mit „float32“-Präzision konvertiert. |
|
mittel |
Das Deep Learning-Modell wird mit „float16“-Präzision konvertiert. |
Die meisten Recheneinheiten unterstützen beide Präzisionseinstellungen. Es gibt jedoch u. U. auch einige Recheneinheiten, die nur eine dieser Einstellungen unterstützen. In diesem Fall ist für den Parameter nur die unterstützte Präzision verfügbar, nachdem das jeweilige Gerät mit dem Parameter „Recheneinheit“ ausgewählt wurde. Bei einer automatischen Auswahl der Recheneinheit, d. h. bei Einstellung von „Recheneinheit“ auf „auto“, ist nur die Präzision „hoch“ verfügbar.
Trainingsparameter
Standard-Trainingsparameter
Breite des Trainingsbilds:
Dieser Parameter definiert die Breite der für das Training verwendeten Bilder. Der Parameter ist standardmäßig auf 480 px festgelegt. Um das Training zu beschleunigen, können Sie die Bildbreite maßstabgerecht verkleinern.
Dieser Parameter muss auf ein Vielfaches von 32 festgelegt werden.
Höhe des Trainingsbilds:
Dieser Parameter definiert die Höhe der für das Training verwendeten Bilder. Der Parameter ist standardmäßig auf 480 px festgelegt. Um das Training zu beschleunigen, können Sie die Bildhöhe maßstabgerecht verkleinern.
Dieser Parameter muss auf ein Vielfaches von 32 festgelegt werden.
Anteil an Pixel:
Dieser Parameter definiert den Anteil der Pixel in den für das Training verwendeten Bildern. Der Parameter ist standardmäßig auf 0,25 festgelegt. Das bedeutet, dass 25 % der Pixel in den Trainingsbildern für das Training verwendet werden. Das Trainingsergebnis kann u. U. verbessert werden, indem der Wert erhöht wird. Dadurch steigt aber auch die Trainingszeit.
Zusätzliche Trainingsparameter
Modellgröße:
Dieser Parameter definiert das vorab trainierte Modell, das für das Training verwendet wird. Standardmäßig ist „mittel“ ausgewählt. Sie können den Parameter auf „groß“ festlegen, um ein großes Modell zu verwenden. Es wird jedoch empfohlen, immer mit dem Standardmodell zu beginnen und das große Modell nur dann zu verwenden, wenn die Leistung des mittleren Modells nicht überzeugend ist. Die beiden Modelle unterscheiden sich hauptsächlich durch die benötigte Größe des Arbeitsspeichers und die Verarbeitungszeit.
Bildkomplexität:
Dieser Parameter beschreibt die Fähigkeit des Modells, komplexe Bilder zu verarbeiten. Der Parameter ist standardmäßig auf 15 festgelegt. Ein höherer Wert kann die Leistung verbessern, erhöht aber die erforderliche Zeit zum Trainieren des Modells.
Maximale Anzahl der Epochen:
Dieser Parameter definiert die maximale Anzahl von Trainingszyklen durch die vollständigen Trainingsdaten. Der Parameter ist standardmäßig auf 15 festgelegt. Falls der durch den Trainingsparameter „Trainingsfehler-Schwellwert“ angegebene Fehlerschwellwert in einer früheren Epoche erreicht wird, wird das Training beendet.
Trainingsfehler-Schwellwert:
Dieser Parameter ist ein Beendigungskriterium für das Training. Der Parameter ist standardmäßig auf 0,001 festgelegt. Das Training wird erfolgreich beendet, sobald der Trainingsfehler unter den angegebenen Fehlerschwellwert sinkt. Der Trainingsfehler wird auch als Trainingsergebnis ausgegeben.
Regulierungsrauschen:
Mit diesem Parameter kann das Training reguliert werden, um die Stabilität zu verbessern. Der Parameter ist standardmäßig auf 0,0 festgelegt. Dies bedeutet, dass kein Regulierungsrauschen erzeugt wird. Falls das Training fehlschlägt, kann die Einstellung eines höheren Werts hilfreich sein.
Ergebnisse
Standardergebnisse
Anomaliebereich:
Dieses Ergebnis stellt den Bereich dar, der alle Pixel umfasst, die als Anomalie angesehen werden.
Anomalie erkannt:
Dieses Ergebnis gibt an, ob das Bild eine Anomalie enthält oder nicht. Der Ergebniswert ist 1, wenn das Bild eine Anomalie enthält. Andernfalls ist der Ergebniswert 0.
Anomaliebewertung:
Dieses Ergebnis gibt die Wahrscheinlichkeit an, dass das ganze Bild eine Anomalie enthält.
Toolstatus:
„Toolstatus“ gibt Informationen zum Status des Tools aus und kann daher für die Fehlerbehandlung verwendet werden. Weitere Informationen zu den verschiedenen Toolstatus-Ergebnissen finden Sie unter Toolstatus-Ergebnis.
Zusätzliche Ergebnisse
Verwendete Recheneinheit:
Dieses Ergebnis gibt die Recheneinheit aus, die in der letzten Iteration verwendet wurde. Anhand dieses Ergebnisses können Sie feststellen, welche Recheneinheit tatsächlich verwendet wurde, wenn der Parameter „Recheneinheit“ auf „auto“ festgelegt ist, bzw. überprüfen, ob die richtige Recheneinheit verwendet wurde.
Datentyp der Präzision:
Dieses Ergebnis gibt den Datentyp aus, der intern für die Optimierung des Deep Learning-Modells für Inferenz verwendet wurde. Anhand dieses Ergebnisses können Sie überprüfen, ob die richtige Präzision verwendet wurde, falls Probleme auftreten.
Wenn der Parameter „Präzision“ auf „hoch“ festgelegt ist, soll das Deep Learning-Modell mit „float32“-Präzision konvertiert werden. Daher wird erwartet, dass dieses Ergebnis den Datentyp „float32“ ausgibt. Wenn der Parameter „Präzision“ auf „mittel“ festgelegt ist, soll das Deep Learning-Modell mit „float16“-Präzision konvertiert werden. In diesem Fall werden für das Ergebnis Werte des Datentyps „float16“ erwartet. Falls bei einer Iteration Ihrer MVApp ein Problem aufgetreten ist, können Sie überprüfen, ob dieses Ergebnis einen anderen Datentyp als erwartet ausgibt. Weitere Informationen finden Sie möglicherweise auch in der Log-Datei. Weitere Informationen zu den Log-Dateien finden Sie auf der Seite Protokollieren.
Verarbeitungszeit:
Dieses Ergebnis gibt die Dauer der letzten Ausführung des Tools in Millisekunden aus. Das Ergebnis wird als zusätzliches Ergebnis bereitgestellt. Es ist daher standardmäßig ausgeblendet, kann aber über die Schaltfläche ![]() neben den Toolergebnissen angezeigt werden. Weitere Informationen finden Sie im Abschnitt Verarbeitungszeit in der Tool-Referenz-Übersicht.
neben den Toolergebnissen angezeigt werden. Weitere Informationen finden Sie im Abschnitt Verarbeitungszeit in der Tool-Referenz-Übersicht.
Heatmap:
Dieses Ergebnis stellt die Heatmap als Bild dar, das die Anomalien visualisiert.
Dargestelltes Bild:
Dieses Ergebnis stellt das Verarbeitungsbild überlagert mit der Anomalieheatmap dar. Da das Verarbeitungsbild hinter der Heatmap sichtbar ist, können Sie deutlicher sehen, welche Anomalie wo im Bild vorhanden ist. Die Heatmap wird jedoch nur angezeigt, wenn der Parameter „Heatmap anzeigen“ auf 1 festgelegt ist. Wenn „Heatmap anzeigen“ auf 0 festgelegt ist, enthält das ausgegebene Bild nur das Verarbeitungsbild ohne Heatmap.
Trainingsergebnisse
Standardtrainingsergebnisse
Trainingsfehler:
Dieses Ergebnis gibt den besten beim Training erreichten Fehler aus.
Zusätzliche Trainingsergebnisse
Schwellwert des Anomaliebereichs – Ausgabe:
Dieses Ergebnis gibt den Schwellwert aus, der zum Bestimmen von Anomaliebereichen im Bild erforderlich ist. Der Ergebniswert ist auch der Eingabeparameter „Schwellwert des Anomaliebereichs“ für den Verarbeitungsschritt.
Schwellwert der Anomaliebewertung – Ausgabe:
Dieses Ergebnis gibt den Schwellwert aus, der bestimmt, ob das Bild als Bild mit einer Anomalie gezählt wird oder nicht. Der Ergebniswert ist auch der Eingabeparameter „Schwellwert der Anomaliebewertung“ für den Verarbeitungsschritt.
Anwendungsbeispiele
Dieses Tool wird in den folgenden MERLIC-Vision-App-Beispielen verwendet:
- detect_anomalies_of_bottles.mvapp
- classify_and_inspect_wood.mvapp

