式を判定
式を判定、すなわちアプリケーションの結果を確認するには、このツールを使用します。この式を構成するのは、前のツールの数値の結果と文字列の結果、または手動で指定した値です。判定には広い範囲の式を使用できます。使用できる式の詳細については、式の節を参照してください。
他の MERLIC ツールと違って、このツールを挿入するときにデフォルトパラメーターはありません。式でパラメーターを使用する場合、手動でツールに追加する必要があります。詳細については、パラメーターの追加の節を参照してください。
グラフィックウィンドウの代わりに、このツールには、この式を定義できる入力フィールドが表示されます。評価された式の結果は、ツールの下部に返ります。このツールを挿入するときにデフォルトパラメーターはありません。
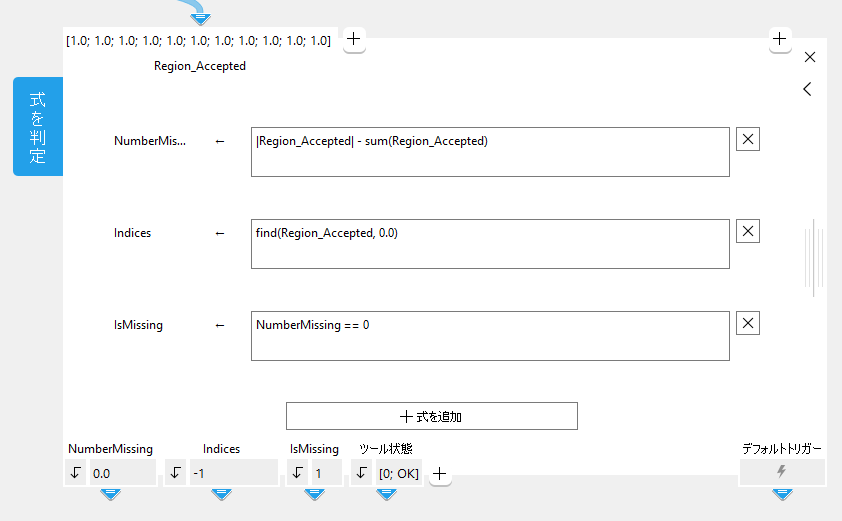
式の入力
式の入力フィールドに入力すると、入力内容に一致する可能性のある関数と演算子を含むオートコンプリートリストがポップアップします。このリストには、手動で追加されたパラメーターと以前に定義された結果も含まれています。これは、このツールの前の式の結果を、そのツールの後続の式で使用できることを意味します (たとえば、最初の式の結果を 3 番目の式で使用するなど)。ただし、後続の式の結果を前の式で使用することはできません (たとえば、3番目の式の結果を最初の式で使用するなど)。
リスト全体から直接参照するには、ショートカット CTRL + スペースキーを使用してポップアップを手動で開きます。指定可能な関数と演算子の詳細については、演算のタイプの節を参照してください。
この画像では、CTRL +スペースキーを使用して手動で開いた後の、可能なすべての関数と演算子を含むポップアップリストを確認できます。リストの一番上に、最初の式「NumberMissing」の結果と、パラメーター「Region_Accepted」が表示されます。
式の追加、削除、および移動
追加の式を手動で追加および削除できます。式を追加するには、ツールワークスペース の下部にある「![]() 式を追加」ボタンをクリックします。入力フィールドの右側にある
式を追加」ボタンをクリックします。入力フィールドの右側にある ![]() ボタンをクリックすると、式を削除できます。
ボタンをクリックすると、式を削除できます。
または、ツールワークスペース の下部にある結果を右クリックし、「削除」を選択して結果とそれぞれの式を削除することもできます。
ドラッグアンドドロップによって、追加した式を移動させ、前の式の結果を次の式で使用できるようにするなど、式の順番を変更できます。そうするには、移動させる式を選択し、ドラッグして目的の位置まで移動させ、新しい場所にドロップします。
新しい式ごとに、新しい結果が作成され、ツールの下部に返されます。オプションで、ツールの下部にある結果名をダブルクリックして、結果の名前を変更します。ツールパラメーターと結果の命名規定については、ツールとコネクターの名前の変更のトピックを参照してください。
結果を非表示にすることができます。たとえば、他のツールに未接続で、ツールフロー のさらに下の式でのみ使用される中間結果がある場合です。非表示にしたい結果を右クリックし、「非表示」を選択します。非表示の結果を表示するには、結果の右側にある ![]() ボタンを使用します。
ボタンを使用します。
パラメーター
このツールにデフォルトパラメーターはありません。したがって、ツールを挿入したときに、パラメーターは表示されません。パラメーター値を式で使用する場合、前のツールの結果値を使用するか、ツールの新しいパラメーターを定義できます。
サポートしているセマンティックタイプ
このツールでは、パラメーターに以下のセマンティックタイプをサポートします:
- 任意
- double
- long
- string
MERLIC で利用できるすべてのセマンティックタイプがこのツールでサポートされているわけではありませんが、「ツール状態」など、この結果のセマンティックタイプがサポートされていなくても、前のツールの数値結果、または文字列結果を使用できます。ただし、その結果に対する接続を作成すると、個々の新しいパラメーターのセマンティックタイプは変換されて、「any」(任意) に設定されます。
セマンティックタイプの「long」は整数でも値の範囲が広い整数を表しますが、以下の解説では引き続き、整数と呼びます。
パラメーターの追加
前のツールの結果をパラメーターとして使用
前のツールの結果をユーザーの式で使用するとき、結果を「式を判定」ツールに接続する必要があります。
- 「式を判定」ツールで結果をパラメーターとして使用する前のツールに移動します。
- 接続の矢印を目的のツール結果から接続のドロップターゲットまでドラッグします。あるいは、コンテキストメニューを開き、メニューエントリ「接続先」をクリックします。
- ツール「式を判定」を選択し、メニューエントリ「<接続を追加>」をクリックします。
接続した結果は、「式を判定」ツールの新しいパラメーターとしてすぐに追加されます。パラメーターの名前とセマンティックタイプは、接続した結果から自動的に適合されます。接続した結果値のセマンティックタイプをこのツールでサポートしていない場合、新しいパラメーターでは、自動的に「any」に設定されます。
あるいは、以下に述べるように、ツールで新しいパラメーターを定義して、新しいパラメーターを前のツールの結果に接続することもできます。
新しいパラメーターの定義
新しいパラメーターを定義するには、新しいコネクターを追加して、パラメーター設定を定義します。
- ツールボードの左上角の
 ボタンをクリックします。パラメーター設定を定義するダイアログウィンドウが開きます。
ボタンをクリックします。パラメーター設定を定義するダイアログウィンドウが開きます。 - このダイアログウィンドウで新しいパラメーターのセマンティックタイプを選択します。
- オプションで新しいパラメーターの最小値と最大値を定義します。
- 「Ok」をクリックして、設定を確定します。新しいパラメーターは、デフォルト名で直ちに追加されます。
- パラメーター名をダブルクリックすると、オプションでパラメーター名を変更できます。ツールパラメーターと結果の命名規定については、 ツールとコネクターの名前の変更の章を参照してください。
- コネクターで新しいパラメーターの値を定義します。
パラメーターのセマンティックタイプと値の範囲を保存すると、これらの設定は以後変更できません。セマンティックタイプや値の範囲を調整する場合は、目的の設定で新しいパラメーターを追加します。
式
評価する式は、ツールボードの入力フィールドに定義してください。式が定義されていないか、無効な式が定義されている場合、MERLIC では、ツールボード と ツールフロー パネルにエラーが表示されます。ただし、このエラーは、式が欠落しているか、式が誤っている場合のみ発行されます。重要なワークスペースエラーは発行されません。したがって、その場合、「ツール状態」結果では「[0; OK]」が返ります。
この式は、数値、 文字列値、混合タプルに適用できます。ツールパラメーターの値を評価に使用するには、パラメーターの名前をこの式の入力フィールドに入力します。パラメーターなしで式を定義することもできます。
評価の方向
式は通常左から右に判定します。ただし、式で括弧を使用すると、判定順序が変化することがあります。
演算のタイプ
演算は、通常、長さ 1 の原子タプル タプルは、数値や文字列などの要素のリストです。を前提に記述します。タプルに複数のエレメントがある場合、ほとんどの演算は以下のように行われます。
- タプルの 1 つが長さ 1 の場合、他のタプルのすべてのエレメントは選択した演算では、その単独値と組み合わせられます。
- 両方のタプルの長さが 1 を超える場合、両方のタプルは同じ長さになります (そうでなければエラーになります)。この場合,選択した演算は同じインデックスのすべてのエレメントに適用されます。得られるタプルの長さは、入力タプルのながさと同じです。
- タプルの 1 つの長さが 0 ([]) の場合、エラーになります。
以下では、式で使用できるさまざまなタイプの演算について解説します。
基本タプル演算には、1 つ以上の値の選択、タプルの組み合わせ (連結)、あるいはエレメント数の取得があります。制御データを持ったタプル上の演算については、以下の表を参照してください。
|
演算 |
説明 |
|---|---|
|
tuple[index] |
指定された tuple 番号の index 要素を選択します。 0 <= index < |tuple| |
|
tuple[index_1:index_2] |
位置 index_1 から index_2 までの tuple 要素を選択します。 |
|
|tuple| |
tuple の要素数を取得します。 |
|
[tuple_1,tuple_2] |
tuple_1 と tuple_2 を連結します。 |
|
[integer_1:integer_2] |
増分値 1 で、integer_1 から integer_2 までの値のシーケンスを生成します。 |
|
[integer_1:integer_2:integer_3] |
integer_1 to integer_3 から、integer_2 の増分値で値のシーケンスを生成します。 |
|
find(tuple_1,tuple_2) |
tuple_1 内にある tuple_2 のすべてのインデックスを取得します (一致がなければ -1 を返します)。 |
|
gen_tuple_const(length,value) |
各要素が同じ値を持つ、事前定義された length の新しいタプルを生成します。長さは整数として定義する必要があります。 |
|
remove(tuple,index) |
指定された index 番号の要素を tuple から削除します。 |
|
select_mask(tuple_1,tuple_2) |
tuple_2 で対応するマスク値が 0 より大きい tuple_1 からすべての要素を選択します。 |
|
subset(tuple,index) |
指定された tuple 番号の index 要素を選択します。単一のインデックス番号またはインデックスのタプルのいずれかを定義できます。 |
|
uniq(tuple) |
連続する同一要素の 1 つを除いてすべてを tuple から破棄します。 |
連結では、入力として、変数または定数を 1 つ以上受け入れます。変数または定数は、角括弧内にすべてリストされ、コンマで区切ります。結果は再びタプルです。注意:[[tuple]] = [tuple] = tuple.
|tuple| はタプルの要素数を返します。ゼロから要素数マイナス 1 までの要素の範囲のインデックス。|tuple|−1。したがって、選択インデックスは、この範囲内におさまるものとします。
|
サンプルタプル |
サンプルの演算 |
|---|---|
|
tuple = [7,8,9] |
tuple[1] = 8 |
|
tuple = [1,2,3,7,8,9] |
tuple[2:4] = [3;7;8] |
|
tuple = [7,8,9] |
|tuple| = 3 |
|
tuple_1 = [1,2,3] tuple_2 = [7,8,9] |
[0,tuple_1,tuple_2,27,89] = [0;1;2;3;7;8;9;27;89] |
|
integer_1 = 7 integer_2 = 13 |
[integer_1:integer_2] = [7;8;9;10;11;12;13] |
|
integer_1 = 1 integer_2 = 2 integer_3 = 10 |
[integer_1:integer_2:integer_3] = [1;3;5;7;9] |
|
tuple_1 = [1,2,3,7,8,9] tuple_2 = [3,7] tuple_3 = [7,3] |
find(tuple_1, tuple_2) = 2 find(tuple_1, tuple_3) = -1 |
|
length = 4 value = 23 |
gen_tuple_const(4,23) = [23;23;23;23] |
|
tuple = [1,2,3,7,8,9] |
remove(tuple, [0,4]) = [2;3;7;9] |
|
tuple_1 = [0,1,2,3,4,5] tuple_2 = [1,1,0,1,0,0] |
select_mask(tuple_1, tuple_2) = [0;1;3] |
|
tuple = [2,4,8,16,16,32] |
subset(tuple, [0,2,4]) = [2;8;16] |
|
tuple = [1,1,0,1,0,0] |
uniq(tuple) = [1;0;1;0] |
以下の基本的演算が使えます。
|
演算 |
説明 |
|---|---|
|
number_1 / number_2 |
除算 |
|
number_1 * number_2 |
乗算 |
|
number_1 % number_2 |
係数 |
|
number_1 + number_2 |
加算 |
|
number_1 - number_2 |
減算 |
|
-number_1 |
否定 |
係数は整数に適用できます。他のすべての演算は、整数または実数に適用できます。ひとつ以上のオペランドのタイプが実数の場合、計算結果も実数になります。
算術演算の例
|
式 |
結果 |
|---|---|
|
4 / 3 |
1 |
|
4 / 3.0 |
1.3333333 |
|
(4 / 3) * 2.0 |
2.0 |
数字のビット演算では、以下の演算を使用できます。オペランドは整数とします。
|
演算 |
説明 |
|---|---|
|
lsh (integer_1,integer_2) |
左シフト。結果は integer_1 のビット単位の左シフトであり、integer_2 回適用します。 |
|
rsh (integer_1,integer_2) |
右シフト。結果は integer_1 のビット単位の右シフトであり、integer_2 回適用します。 |
|
integer_1 band integer_2 |
ビット単位で論理積 |
|
integer_1 bxor integer_2 |
ビット単位で排他的論理和 |
|
integer_1 bor integer_2 |
ビット単位で論理和 |
|
bnot integer |
ビット単位で補集合 |
演算 lsh と rsh の場合、2 番目のオペランドの値が負であるか、32 よりも大きいと、結果は未定義になります。
これらは文字列を修正、選択、結合するのに使える複数の文字列演算です。また、一部の演算では、整数と実数を文字列に変換できます。
|
演算 |
説明 |
|---|---|
|
value $ string |
仕様 string で value を変換します。詳細については、$ (文字列の変換) の節を参照してください。 |
|
value_1 + value_2 |
value_1 と value_2 を連結します。値の少なくとも 1 つは文字列である必要があります。 |
|
strchr(string, char) |
string で文字 char の最初の出現の 1 文字を検索します。 |
|
strrchr(string, char) |
string で文字 char の最後の出現の 1 文字を検索します (逆)。 |
|
strstr(string_1, string_2) |
string_1 で最初に出現する部分文字列 string_2 を検索します。 |
|
strrstr(string_1, string_2) |
string_1 で最後に出現する部分文字列 string_2 を検索します (逆)。 |
|
strlen(string) |
string の長さを返します。 |
|
string{index} |
位置 index の文字を選択します。 0 <= index <= strlen(string)-1. |
|
string{index_1:index2} |
位置 index_1 から位置 index_2 までの従属文字を選択します。 |
|
split(string_1, string_2) |
string_2 の従属文字の string_1 を分割します |
|
regexp_match(string_1, string_2) |
正規表現 string_2 と一致する string_1 の従属文字を抽出します。 |
|
regexp_replace(string_1, regex, string_2) |
正規表現 regex と一致する string_1 の最初の従属文字を、string_2 と置換します。 |
|
regexp_select(string, regex) |
string から、正規表現 regex と一致するタプル要素を選択します。 |
|
regexp_test(string, regex) |
string でいくつのタプル要素が正規表現 regex と一致するかを返します。 |
|
サンプル文字列 |
サンプルの演算 |
|---|---|
|
string = '0,7f' |
4 $ 'string' = "4.0000000" |
|
value_1 = 'good' value_2 = 'morning' |
value_1 + value_2 = 'goodmorning' |
|
string = 'exemplary' |
strchr(string, 'xyz') = 1 |
|
string = 'exemplary' |
strrchr(string, 'xyz') = 8 |
|
string_1 = 'mississippi' string_2 = 'ss' |
strstr(string_1, string2) = 2 |
|
string_1 = 'mississippi' string_2 = 'ss' |
strrstr(string_1, string2) = 5 |
|
string = 'incomprehensibilities' |
strlen(string) = 21 |
|
string = 'abaaabbaababaa' |
string{7} = "a" |
|
string = 'abaaabbaababaa' |
string{7:10} = "aaba" |
|
string_1 = 'appendix.pdf' string_2 = '.' |
split(string_1, string_2) = [appendix;pdf] or split(string_1, 'pp') = [a;endix.;df] |
|
string_1 = ['XXS001.JPG', 'XXS002.JPG', 'XXS003.JPG'] string_2 = 'XXS(.*)' |
regexp_match(string_1, string_2) = [001.JPG, 002.JPG, 003.JPG] |
|
string_1 = 'goodmorning' regex = 'g' string_2 = 'G' |
regexp_replace(string_1, regex, string_2) = "Goodmorning" |
|
string = ['img1.jpg', 'img2.png'; 'appendix.pdf', my_dir'] regex = '.(jpg|png)' |
regexp_select(string, regex) = ['img1.jpg', 'img2.png'] |
|
string = ['img1.jpg', 'img1.png', 'img2.jpg', 'img2.png'] regex = '(.png)' |
regexp_test(string, regex) = 2 |
個々の文字列演算の詳細解説も参照してください。
$ は数字を文字列に変換するか、文字列に変更します。$ の左のオペランドは、変換した数字です。$ の右のオペランドは、変換を指定します。C プログラミング言語の printf() 関数の形式文字列と互換性があります。形式文字列を構成するのは、以下の 4 つの部分です。
<flags><width>.<precision><conversion>
または、以下の正規表現です。
[-+ #]?([0-9]+)?(\.[0-9]*)?[doxXfeEgGsb]?
正規表現は、最初の角括弧のペアにある、ゼロ以上の数字が続く (さらに任意で、ドットが続く場合もあります。このドットの後には最後の角括弧ペアの変換文字が続く数字が続く場合もあります) ゼロ個以上の文字を概算変換します。
文字列変換の例$
|
式 |
結果 |
|---|---|
|
23 $ '10.2f' |
"23.00" → ".....23.00" |
|
23 $ '-10.2f' |
"23.0 " → "23.00....." |
|
4 $ '.7f' |
"4.0000000" |
|
1234.56789 $ '+10.3f' |
" +1234.568" |
|
255 $ 'x' |
"ff" |
|
255 $ 'X' |
"FF" |
|
0xff $ '.5d' |
"00255" |
|
'total' $ '10s' |
"total" → ".....total" |
|
'total' $ '-10s' |
"total " → "total....." |
|
'total' $ '10.3' |
"tot"→ ".......tot" |
追加の空白がある結果については、わかりやすいよう、2 回目から「.」を明記しますが、これは入力文字列前後に追加される空白を表します。たとえば、文字列「total.....」は、最後の 5 個のドットは空白を表します。
形式文字列の個々の部分を以下に示します。
フラグ:
任意の順序のゼロ個以上のフラグ。これで、変換仕様の意味が変わります。フラグには以下の文字を使用できます。
フラグ
説明
-
変換結果はフィールド内で左詰めになります。
+
符号付き変換をすると、必ず符号 (+ または -) が先頭に付きます。
スペース
符号付き変換の最初の文字が符号でない場合、結果の先頭はスペース文字になります。
#
この値は、「代替形式」に変換します。
d と s 変換 (以下参照) の場合、このフラグに意味はありません。
o 変換 (以下参照) の場合、精度が上がって結果の先頭桁はゼロになります。
x または X 変換 (以下参照) の場合、結果がゼロ以外の場合、先頭は 0x または 0X になります。
e、E、f、g、G 変換の場合、基数文字の後に数字が続かなくても結果には必ず基数文字が含まれます。
g 変換と G 変換の場合、通常の動作と異なり、後続のゼロは結果から削除されません。
幅:
最小文字列フィールド幅を指定する任意の 10 進数。出力フィールドの場合、変換値の文字数がフィールド幅より少ないと、フィールド幅で左詰め (左調整フラグを指定した場合は右詰め) になります。
精度:
精度は、整数変換で表示される最小桁数 (フィールドの先頭にはゼロが埋め込まれる)、e 変換と f 変換で基数文字の後に表示される桁数、g 変換の最大有効桁数、または文字列変換で出力される最大文字数を指定します。精度の形式では、ピリオド . の後に 10 進数文字列が続きます。ヌル桁文字列は、ゼロ扱いです。
変換:
変換文字は、適用する変換タイプを表します。
変換文字
説明
d, o, x, X
整数引数は、符号付き 10 進数 (d), 符号なし 8 進数 (o)、または符号なし 16 進数表記法 (x と X) で出力します。
x 変換では、数字と小文字 0123456789abcdef を使用します。また X 変換では、数字と大文字 0123456789ABCDEF を使用します。引数の精度コンポーネントは、表示する最小桁数を指定します。
変換する値が、指定最小数よりも少ない桁数で表現できる場合、先頭のゼロで拡張されます。デフォルト精度は 1 です。ゼロ値変換の結果は、精度 0、文字なしです。
f
浮動小数点数の引数は、10 進表記法、スタイル [-]ddd.ddd で出力されます。基数文字の後の桁数は精度仕様と同じです。
引数で精度を省略すると、6 桁が出力されます。精度が明示的に 0 の場合、基数は表示されません。
e、E
浮動小数点数引数はスタイル [-]d.ddde+dd で出力されます。ここで、基数文字の前の 1 桁と、基数文字の後の桁数が精度になります。
精度を省略すると、6 桁が適用されます。精度が 0 の場合、基数文字は表示されません。
E 変換文字は、e ではなく指数を導く E 付き数字を生成します。指数は必ず 2 桁以上になります。ただし、出力する値に 2 桁より大きな指数が必要な場合、必要に応じて追加の指数桁数が出力されます。
g, G
浮動小数点数引数は、有効桁数を指定する精度とともに f または e のスタイルで出力されます (または G 変換文字の場合、スタイル E で)。
使用するスタイルは変換する値によって異なります。スタイル e は、変換で得られる指数が -4 未満または精度以上の場合のみ使用します。後続のゼロは、結果から削除されます。基数文字は後に数字が続く場合のみ表示されます。
s
引数は文字列の形を取り、文字列の文字は文字列の最後まで、または引数の精度仕様で指定した文字数に達するまで出力されます。
引数の精度を省略すると、無限大に解釈され、文字列の最後までの文字がすべて出力されます。
フィールド幅がゼロまたは不足してもフィールドの切り詰めは行われません。変換結果がフィールド幅より広い場合、フィールドは変換結果に合わせて拡張されます。
文字列の連結 (+) は、文字列との組み合わせまたはすべての数値タイプに適用できます。必要に応じて、オペランドは、(その標準表記に従って) まず文字列に変換されます。演算子を文字列連結として機能させるためには、少なくとも 1 つ以上のオペランドをあらかじめ文字列にしておきます。
文字列の連結例
|
式 |
結果 |
|---|---|
|
'Name'+Counter+'.png' |
たとえば、「Name2.png」 |
例では、ファイル名 (たとえば、「Name2.png」) が生成されます。そのため、2 つの文字列定数 (「Name」と「.png」) および整数値 (loop-index カウンタ) が連結されます。
strchr(string,char)は、string において、文字 char の最初の出現の 1 文字のインデックスを返し、strrchr(string,char) は、string において文字 char の最後の出現の 1 文字のインデックスを返します。string に当該文字がなければ、-1 が返されます。string は、単独文字列または文字列のタプルです。
str(r)chr の例
|
式 |
結果 |
|---|---|
|
strchr('abaaab','a') |
0 |
|
strrchr('abaaab','a') |
4 |
strstr(string_1,string_2) は、string_1 で最初に出現する string_2 のインデックスを返し、strrstr(string_1,string_2) は string_1 で最後に出現する string_2 のインデックスを返します。string_2 が string_1 にない場合、-1 が返されます。string_1 は、単独文字列または文字列のタプルです。
str(r)str の例
|
式 |
結果 |
|---|---|
|
strstr('abaaab','ab') |
0 |
|
strrstr('abaaab','ab') |
4 |
strlen(string) は、string 内の文字数を返します。
strlen の例
|
式 |
結果 |
|---|---|
|
strlen('abaaab') |
6 |
string{index} は、(インデックス位置で指定された) 単独文字を string から選択します。インデックスの範囲は、ゼロから string の長さマイナス 1 までです。演算子の結果は長さ 1 の文字列です。
string{index_1:index_2} は、s 内で最初に指定したインデックス位置 (index_1) から、第 2 の指定位置 (index_2) までのすべての文字を文字列として返します。インデックスの範囲は、ゼロから string の長さマイナス 1 までです。
{} の例
|
式 |
結果 |
|---|---|
|
'abaaab'{1} |
"b" |
|
'abaaab'{1:5} |
"baab" |
split(string_1,string_2) は、string_1 を単一従属文字列に分割します。String_1 は、string_2 の文字がある位置で分割されます。
split の例
|
式 |
結果 |
|---|---|
|
split('/usr/image:/usr/proj/image',':') |
["/usr/image";"/usr/proj/image"] |
文字列は、文字「:」の位置で、2 つの従属文字列に分割されます。従属文字列はタプルで返ります。
regexp_match(string_1,string_2) は、正規表現 string_2 と一致するタプル string_1 要素を検索しますregexp_match(s1,s2) は、入力タプルと同じサイズのタプルを返します。得られるタプルでは、入力タプルの各タプル エレメントのマッチング結果が返ります。マッチングが成功すると、マッチング従属文字列が返ります。それ以外は、空の文字列が返ります。
regexp_match の例
|
式 |
結果 |
|---|---|
|
regexp_match('abba','b+a*') |
"bba" |
|
regexp_match(['img123','img124'],'img(.*)') |
["123";"124"] |
regexp_replace(string_1,regex,string_2) 正規表現 regex と一致する string_1 の従属文字列を string_2で得られた文字列と置換します。デフォルトでは、 string_1の各要素の一致する最初の従属文字のみが置換されます。すべての出現を置換するには、オプション 'replace_all'を regexに設定する必要があります。
regexp_replace の例
|
式 |
結果 |
|---|---|
|
regexp_replace('abaaab','a','b') |
"bbaaab" |
|
regexp_replace('abaaab',['a','replace_all'],'b') |
"bbbbbb" |
regexp_select(string_1,regex) は正規表現 regex と一致するタプル string_1 の要素のみを返します。regexp_match と違って、マッチング従属文字列の代わりにオリジナルタプルエレメントが返されます。正規表現と一致しないタプルエレメントは廃棄されます。さらに、regexp_select は、オプション 'invert_match' をサポートしています。このオプションでは、正規表現と一致しない入力文字列が選択されます。
regexp_select の例
|
式 |
結果 |
|---|---|
|
regexp_select(['mydir', 'a.png', 'b.txt', 'c.bmp', 'd.dat'], '.(bmp|png)') |
["a.png"; "c.bmp"] |
|
regexp_select(['mydir', 'a.png', 'b.txt', 'c.bmp', 'd.dat'], ['.(bmp|png)', 'invert_match']) |
["mydir"; "b.txt"; "d.dat"] |
regexp_test(string,regex) は、正規表現 regex と一致するタプル string の要素数を返します。さらに、演算子の短縮形も利用できますが、これは条件付き式で便利です。 string_1 =~ string_2
|
式 |
結果 |
|---|---|
|
regexp_test(['mydir','a.png','b.txt','c.bmp','d.dat'],'.(bmp|png)') |
2 |
|
['mydir','a.png','b.txt','c.bmp','d.dat'] =~ '.(bmp|png)' |
2 |
以下の比較演算を判定できます。任意の数のエレメントがあるタプルでも定義します。常にブール値を返します。
|
演算 |
説明 |
|---|---|
|
tuple_1 < tuple_2 |
未満 |
|
tuple_1 > tuple_2 |
より大きい |
|
tuple_1 <= tuple_2 |
以下 |
|
tuple_1 >= tuple_2 |
以上 |
|
tuple_1 == tuple_2 ; tuple_1 = tuple_2 |
等しい |
|
tuple_1 != tuple_2 ; tuple_1 # tuple_2 |
等しくない |
tuple_1 == tuple_2 と tuple_1 != tuple_2 はすべてのタイプで定義されます。2 つのタプルの長さが同じで、それぞれのインデックス位置のデータ項目が等しい場合、その 2 つのタプルは等しくなります (真)。オペランドのタイプが異なる場合 (整数と実数)、整数値は最初に実数に変換されます。タイプ文字列値は数字と組み合わせることはできません。すなわち、文字列値は他のタイプの値とは等しくない扱いです。
タプルの比較例
|
第 1 オペランド |
演算 |
第 2 オペランド |
結果 |
|---|---|---|---|
|
1 |
== |
1.0 |
1 |
|
[] |
== |
[] |
1 |
|
'' |
== |
[] |
0 |
|
[1,'2'] |
== |
[1,2] |
0 |
|
[1,2,3] |
== |
[1,2] |
0 |
|
[4711,'Hugo'] |
== |
[4711,'Hugo'] |
1 |
|
'Hugo' |
== |
'hugo' |
0 |
|
2 |
> |
1 |
1 |
|
2 |
> |
1.0 |
1 |
|
[5,4,1] |
> |
[5,4] |
1 |
|
[2,1] |
> |
[2,0] |
1 |
|
true |
> |
false |
1 |
|
'Hugo' |
< |
'hugo' |
1 |
4 つの比較演算は、タプルの辞書の順序を計算します。同じインデックス位置では、タイプは等しいものとします。ただし、値のタイプである、整数、実数、ブール値は自動的に適用されます。辞書の順序は文字列に適用され、ブール値の偽は、ブール値真より小さいと判断します (偽 < 真)。
これらの比較演算では、入力タプル tuple_1 と tuple_2 の要素を比較します。
|
演算 |
説明 |
|---|---|
|
tuple_1 [<] tuple_2 |
未満 |
|
tuple_1 [>] tuple_2 |
より大きい |
|
tuple_1 [<=] tuple_2 |
以下 |
|
tuple_1 [>=] tuple_2 |
以上 |
|
tuple_1 [==] tuple_2 ; tuple_1 [=] tuple_2 |
等しい |
|
tuple_1 [!=] tuple_2 ; tuple_1 [#] tuple_2 |
等しくない |
両方のタプルの長さが等しい場合、両方のタプルの対応するエレメントを比較します。それ以外は、tuple_1 と tuple_2 のいずれかの長さが 1 になります。その場合、長い方のタプルの各エレメントで比較がもう一方のタプルの単独エレメントに対して行われます。タプルエレメント比較では、対応する 2 つのエレメントは,両方が (整数または浮動小数点) 数字または文字列であることが前提条件です。
タプルのエレメント比較の例
|
第 1 オペランド |
演算 |
第 2 オペランド |
結果 |
|---|---|---|---|
|
[1,2,3] |
[<] |
[3,2,1] |
[1;0;0] |
|
['a','b','c'] |
[==] |
'b' |
[0;1;0] |
|
['a','b','c'] |
[<] |
['b'] |
[1;0;0] |
以下のブール演算を判定できます。
|
演算 |
説明 |
結果 |
|---|---|---|
|
boolean_1 and boolean_2 |
Logical "and" |
1 (真) 両方のオペランドが真のとき。 |
|
boolean_1 xor boolean_2 |
Logical "xor" |
1 (真) 両方のオペランドの一方が真のとき。 |
|
boolean_1 or boolean_2 |
Logical "or" |
1 (真) オペランドの 1 つ以上が真のとき。 |
|
not boolean |
Negation |
1 (真) 入力が偽で 0 のとき (偽) 入力が真のとき |
ブール演算 and, xor, or、および not は、長さ 1 のタプルの場合のみ定義されます。
以下の三角関数を判定できます。
|
関数 |
説明 |
|---|---|
|
sin(numbers) |
numbers の正弦 |
|
cos(numbers) |
numbers の余弦 |
|
tan(numbers) |
numbers の正接 |
|
asin(numbers) |
間隔の逆正弦 numbers |
|
acos(numbers) |
間隔の逆余弦 numbers |
|
atan(numbers) |
間隔の逆正接 numbers |
|
atan2(numbers_1,numbers_2) |
間隔の逆正接 numbers_1/numbers_2 |
|
sinh(numbers) |
numbers の双曲線正弦 |
|
cosh(numbers) |
numbers の双曲線余弦 |
|
tanh(numbers) |
numbers の双曲線正接 |




これらすべての関数は、引数として数字のタプルで機能します。入力は、整数型か実数型です。しかし結果として得られるタイプは実数タイプです。これらの関数は、すべてのタプル値に適用され、得られるタプルは入力タプルと同じ長さになります。atan2 の場合、2 つの入力タプルは同じ長さになります。三角関数については、角度はラジアンで規定されます。
以下の指数関数を判定できます。
|
関数 |
説明 |
|---|---|
|
exp(numbers) |
指数関数 |
|
log(numbers) |
自然対数 ln(numbers)、numbers > 0 |
|
log10(numbers) |
10 を底とする対数、log10(numbers)、numbers > 0 |
|
pow(numbers_1,numbers_2) |
|
|
ldexp(numbers_1,numbers_2) |
|



これらすべての関数は、引数として数字のタプルで機能します。入力は、整数型か実数型です。しかし結果として得られるタイプは実数タイプです。これらの関数は、すべてのタプル値に適用され、得られるタプルは入力タプルと同じ長さになります。pow と ldexp の場合、2 つの入力タプルは同じ長さになります。
以下の数値関数を判定できます。
|
関数 |
説明 |
|---|---|
|
abs(numbers) |
numbers (整数または実数) と同じタイプの絶対値を返します。 |
|
ceil(numbers) |
numbers 以上の最小整数値。 この関数は、整数と実数に機能します。 得られる値は、常に実数型です。 |
|
cumul(tuple) |
対応する tuple 要素の累積合計が返ります。1 つ以上の要素が実数型であれば、結果として得られる値は実数型です。すべての要素が整数型であれば、得られる値も整数型になります。 |
|
deg(numbers) |
numbers をラジアンから度数に変換します。この関数は、整数と実数に機能します。得られる値は、常に実数型です。 |
|
deviation(tuple) |
tuple の標準偏差を計算します。この関数は、整数と実数に機能します。得られる値は、常に実数型です。 |
|
fabs(numbers) |
numbers (常に実数) の絶対値。この関数は、整数と実数に機能します。得られる値は、常に実数型です。 |
|
floor(numbers) |
numbers 以下で最大の整数値が返ります。この関数は、整数と実数に機能します。 得られる値は、常に実数型です。 |
|
fmod(numbers_1, numbers_2) |
numbers_1/numbers_2 の端数部分が、numbers_1 と同じ符号で返ります。この関数は、整数と実数に機能します。得られる値は、常に実数型です。 |
|
int(numbers) |
実数 numbers を整数に変換して端数を切り捨てます。numbers は整数なので、入力値が返ります. |
|
max(tuple) |
tuple の最大値を選択します。これらの値はすべて文字列型、整数、実数のいずれかとします。文字列を数値と混合することはできません。1 つ以上の要素が実数型であれば、結果として得られる値は実数型です。すべての要素が整数型であれば、得られる値も整数型になります。 |
|
max2(tuple_1, tuple_2) |
tuple_1 と tuple_2 の間で要素ごとに大きいほうを選択します。 |
|
mean(tuple) |
tuple の平均値を計算します。この関数は、整数と実数に機能します。得られる値は、常に実数型です。 |
|
median(tuple) |
tuple の中央値を計算します。1 つ以上の要素が実数型であれば、結果として得られる値は実数型です。すべての要素が整数型であれば、得られる値も整数型になります。 |
|
min(tuple) |
tuple の最小値を選択します。 これらの値はすべて文字列型、整数、実数のいずれかとします。文字列を数値と混合することはできません。1 つ以上の要素が実数型であれば、結果として得られる値は実数型です。すべての要素が整数型であれば、得られる値も整数型になります。 |
|
min2(tuple_1, tuple_2) |
tuple_1 と tuple_2 の間で要素ごとに小さいほうを選択します。 |
|
rad(numbers) |
numbers を度数からラジアンに変換します。この関数は、整数と実数に機能します。得られる値は、常に実数型です。 |
|
real(numbers) |
整数 numbers を実数値に変換します。numbers が実数値の場合、入力値が返ります. |
|
round(numbers) |
実数 numbers を整数に変換して値を四捨五入します。 |
|
select_rank(tuple, index) |
tuple の index の位置で要素を返します。この関数は、整数を含むタプルまたは実数値に機能します。index は整数型です。 |
|
sgn(numbers) |
値の符号またはタプルの要素毎の符号 |
|
sqrt(numbers) |
numbers の平方根を計算します。この関数は、整数と実数に機能します。 得られる値は、常に実数型です。 |
|
sum(tuple) |
すべての tuple 要素または文字列連結の合計を計算します。これらの値はすべて文字列型、整数、実数のいずれかとします。文字列を数値と混合することはできません。1 つ以上の要素が実数型であれば、結果として得られる値は実数型です。すべての要素が整数型であれば、得られる値も整数型になります。値変数が文字列の場合、加法の代わりに文字列連結が適用されます。 |
以下の関数を判定できます。
|
関数 |
説明 |
|---|---|
|
chr(numbers) |
ASCII 数字を文字に変換します。 |
|
chrt(integer) |
整数のタプルを文字列に変換します。 |
|
environment(string) |
環境変数の値。string は、文字列としての環境変数の名前です。 |
|
inverse(tuple) |
tuple 値の順序を反転します。tuple が長さ 1 で空の場合、すべての位置に値が 1 つだけの tuple の場合、たとえば [1,1,...,1] であれば、inverse は sort と等しくなります。 |
|
is_number(value) |
value が数字かどうかをテストします。value の型が、整数、実数、または数字を表す文字列の場合、1 (真) が返ります。 |
|
number(value) |
数字の型に応じて、数字を表す文字列を整数か実数に変換します。0x で始まる文字列は 16 進数として解釈され、0 (ゼロ) で始まる文字列は 8 進数として解釈されます。たとえば文字列「20」は整数 20 に、「020」は 16 に、「0x20」は 32 に変換されます。数字を表さない文字列、あるいは整数型や実数型の変数で呼び出すと、数字で返るのは入力のコピーです。 |
|
ord(numbers) |
整数としての文字の ASCII 数字。 |
|
ords(string) |
文字列のタプルを ASCII 整数のタプルに変換します。 |
|
rand(numbers) |
乱数を作成します。 |
|
sort(tuple) |
tuple を昇順に整列します。したがって、得られるタプルの最初の値が最小値になります。タプルが長さ 1 で空の場合、すべての位置に値が 1 つだけのタプルの場合、例、[1,1,...,1], sort は、inverse と等しくなります。 |
|
sort_index(tuple) |
tuple は昇順に整列されますが、整列した値のインデックス位置が返ります。 |
以下の表は、制御データの演算の優先順位です (上から下に増加)。一部の演算 (関数、| |、tuple[]、など) は除外されていますが、これらの演算では、引数が明確にマークされるためです。
|
優先度の順序は上から下 |
|---|
|
band |
|
bxor bor |
|
and |
|
xor or |
|
!= == # = |
|
<= >= < > |
|
+ - |
|
/ * % |
|
- (unary minus) not |
|
$ |
特殊文字の使用
このツールは、単一引用符で文字列を表します。ただし、特殊文字と単一引用符を併用すると、「\t」 のように文字はバックスラッシュでエスケープされ、タブとして処理されます。
以下の表は、特殊文字の一覧です。
|
サロゲート表記 |
説明 |
|---|---|
|
\n |
改行 |
|
\t |
水平タビュレー |
|
\v |
垂直タビュレー |
|
\b |
バックスペース |
|
\r |
復帰改行 |
|
\f |
フォームフィード |
|
\a |
ベル |
|
\\ |
バックスラッシュ |
|
\' |
単一引用符 |
以下の例では、Parameter = \t でパラメーターを使用した場合に得られる値を示しています:
|
式 |
結果 |
説明 |
|---|---|---|
|
Parameter |
\t |
\t は文字列として処理されます。 |
|
strlen(Parameter) |
2 |
\t は 2 文字の文字列として処理されます。 |
|
strlen('\t') |
1 |
\t はタビュレーター文字として処理されます。 |
|
'a\tb' |
a b |
\t はタビュレーターとして処理されます。 |
|
ords(Parameter) |
[92;116] |
\t は文字列として処理されます。 |
|
ords('\t') |
9 |
\t はタビュレーター文字として処理されます。 |
結果
基本結果
結果:
この結果では、式の結果値が返ります。デフォルトでは、これは最初の式の結果です。追加の各式は、追加の結果を返します。結果のセマンティックタイプは、「any」(任意) に設定されます。
ツール状態:
「ツール状態」はツール状態の情報を返します。したがって、エラー処理に使うことができます。さまざまなツールの状態結果の詳細については、 ツール状態 結果 のトピックを参照してください。
追加結果
処理時間:
この結果は、ツールの直近の実行の持続時間をミリ秒単位で返します。結果は、追加結果として提供されます。したがって、デフォルトでは非表示になっていますが、ツール結果の横にある ![]() ボタンを使用して表示できます。詳細については、ツールリファレンス概要の処理時間の節を参照してください。
ボタンを使用して表示できます。詳細については、ツールリファレンス概要の処理時間の節を参照してください。
アプリケーションの例
このツール、以下の MERLIC Vision App 例で使用します:
- adapt_brightness_for_measuring.mvapp
- calibrate_for_ruler_changed_distance.mvapp
- calibrate_for_ruler_distorted.mvapp
- calibrate_for_ruler_simple.mvapp
- check_bent_leads.mvapp
- check_correct_filling_on_3d_height_images.mvapp
- check_pen_parts.mvapp
- check_presence_of_fuses.mvapp
- check_saw_angles.mvapp
- check_single_switches.mvapp
- classify_pills.mvapp
- count_bottles_with_deep_learning.mvapp
- detect_only_scratches_with_photometric_stereo.mvapp
- determine_circle_quality.mvapp
- evaluate_ecc_200_print_quality.mvapp
- find_and_count_screw_types.mvapp
- measure_distance_segment_circle_calibrated.mvapp
- measure_distance_to_center_led.mvapp
- recognize_color_of_cables.mvapp
- segment_pill_defects.mvapp
- segment_pills_by_shape.mvapp

