Mit Deep Learning zählen
Mit diesem Tool können Sie mit einem auf Deep Learning basierenden Verfahren Objekte in verschiedenen Orientierungen und Skalierungen zählen.
Dieses Tool wird mit einem Trainingsmodus verwendet. Dabei wird zunächst ein Training basierend auf Trainingsbildern, die die Referenzobjekte definieren, und festgelegten Trainingsparametern durchgeführt. Beim Training werden abhängig von den angegebenen Trainingsparametern weitere Trainingsbilder generiert, um die Stabilität in Hinblick auf unterschiedliche Orientierungen und Skalierungen zu verbessern.
Der Trainingsbereich befindet sich auf der linken Seite des Toolboards. Er bietet die Möglichkeit, zwischen dem Verarbeitungsmodus für die Zählung und dem Trainingsmodus zu wechseln. Im Grafikfenster wird das Bild des derzeit aktiven Modus angezeigt, der im Trainingsbereich blau hervorgehoben wird. Zusätzlich zu den Suchparametern oben links stellt das Tool oben rechts im Tool weitere Parameter für das Training bereit. Weitere Informationen zur Verwendung von Tools, für die ein Training erforderlich ist, finden Sie unter Im Trainingsmodus arbeiten.
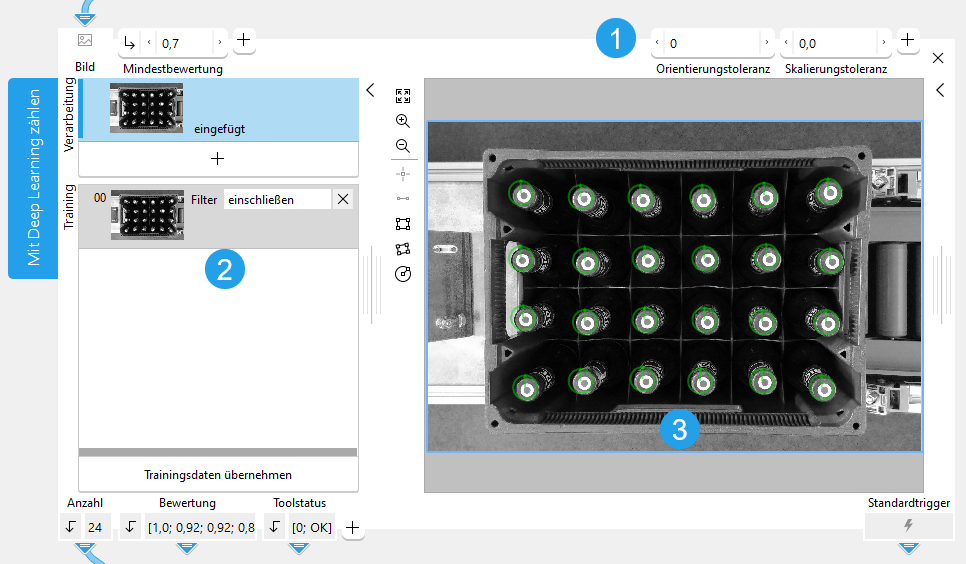
![]() Trainingsparameter
Trainingsparameter
![]() Trainingsbereich
Trainingsbereich
![]() Grafikfenster
Grafikfenster
Angezeigte Bilder
Im Trainingsbereich werden das Verarbeitungsbild und die Trainingsbilder angezeigt.
- Verarbeitungsbild: Das aktuelle „Bild“, das von einem vorherigen Tool stammt.
- Trainingsbilder: Die Bilder, die zum Trainieren des Deep Learning-Modells verwendet werden.
Training
Um das Deep Learning-Modell zu trainieren, müssen Sie zuerst mindestens ein zu zählendes Referenzobjekt definieren und die Trainingsparameter entsprechend anpassen. Es ist auch möglich, mehrere Referenzobjekte zu definieren. In diesem Fall müssen Sie ein Trainingsbild für jedes Referenzobjekt hinzufügen. Nachdem das Training durchgeführt wurde, können Sie die Ergebnisse überprüfen und ggf. weitere Anpassungen vornehmen.
Referenzobjekte definieren
- Fügen Sie über die Schaltfläche
 oder die Taste F3 ein Trainingsbild hinzu, dass das zu zählende Objekt darstellt.
oder die Taste F3 ein Trainingsbild hinzu, dass das zu zählende Objekt darstellt. - Legen Sie den Filtertyp für das Trainingsbild auf „einschließen“ fest.
- Zeichnen Sie im Trainingsbild eine ROI über dem Objekt, das gezählt werden soll. Dieses Objekt wird als Referenzobjekt für das Training verwendet.
- Fügen Sie ein neues Trainingsbild mit dem Filtertyp „einschließen“ hinzu, wenn Sie ein weiteres Objekt zählen möchten, und zeichnen Sie eine ROI über dem betreffenden Referenzobjekt. Sie können diesen Vorgang für jeden Objekttyp wiederholen, den Sie in den Bildern zählen möchten.
- Sie können auch ein oder mehrere Trainingsbilder mit dem Filtertyp „ausschließen“ hinzufügen, um Objekte zu definieren, die nicht gezählt werden sollen. Dies kann nützlich sein, wenn es ähnlich aussehende Objekte gibt, die nicht in der Zählung berücksichtigt werden sollen.
- Führen Sie das Training durch und überprüfen Sie die Ergebnisse, um festzustellen, ob die aktuellen Einstellungen für die definierten Referenzobjekte in Ordnung sind. Wenn die Objekte jedoch in anderen Orientierungen und Skalierungen erkannt werden sollen, können Sie die Trainingseinstellungen wie im nächsten Abschnitt beschrieben zuerst anpassen.
Das Tool kann lediglich ein Objekt pro Trainingsbild trainieren. Daher dürfen Sie nur ein Objekt pro Trainingsbild auswählen. Wenn Sie mehrere ROIs zu einem Trainingsbild hinzufügen, werden sie als ein zusammengesetztes Objekt betrachtet.
Trainingseinstellungen definieren und Training anwenden
Die Trainingsparameter können zum Konfigurieren von Einstellungen für verschiedene Orientierungen und Skalierungen verwendet werden. Mit den Standardeinstellungen der Trainingsparameter wird das Deep Learning-Modell lediglich für die Erkennung von Objekten in der Orientierung und Skalierung gemäß Definition im jeweiligen Trainingsbild trainiert.
- Passen Sie den Trainingsparameter „Orientierungstoleranz“ an, wenn die zu zählenden Objekte in anderen Orientierungen vorkommen können.
- Passen Sie den Trainingsparameter „Skalierungstoleranz“ entsprechend an, wenn die zu zählenden Objekte in den Bildern unterschiedlich skaliert sein können.
- Führen Sie das Training durch und überprüfen Sie die Ergebnisse wie im nächsten Abschnitt beschrieben, um festzustellen, ob die aktuellen Einstellungen in Ordnung sind.
Bei Anwendung des Trainings werden automatisch weitere Trainingsbilder mit unterschiedlichen Orientierungen und Skalierungen der Objekte generiert. Die Anzahl der zusätzlichen Trainingsbilder, die beim Training generiert werden, hängt von den Einstellungen der Trainingsparameter ab. Je größer die Werte für „Orientierungstoleranz“ und „Orientierungstoleranzstufe“ sind, desto mehr Bilder werden für das Training generiert.
Die Werte der Trainingsparameter beeinflussen sowohl die Dauer des Trainings als auch die Verarbeitungszeit. Je mehr zusätzliche Trainingsbilder beim Training erstellt werden, desto länger dauert das Trainieren des Modells. Während der Verarbeitung dauert die Erkennung der zu zählenden Objekte ebenfalls länger, da das Tool die Objekte in verschiedenen Orientierungen und Skalierungsfaktoren sucht.
Es wird empfohlen, die Werte von „Orientierungstoleranz“ und „Skalierungstoleranz“ gerade so groß festzulegen, dass alle gewünschten Objekte gefunden und gezählt werden, aber nicht größer, damit das Training nicht länger dauert als notwendig.
Wenn die Orientierung der zu zählenden Objekte bekannt ist, können Sie die bekannten Orientierungen trainieren, indem Sie ein neues Trainingsbild für jede Orientierung hinzufügen, in der die Objekte vorkommen können. Wenn die Objekte beispielsweise immer mit einer Orientierung von 0° oder 90° vorkommen, können Sie zwei Trainingsbilder hinzufügen: ein Bild, in dem ein Referenzobjekt mit einer Orientierung von 0° definiert ist, und ein Bild, in dem ein Referenzobjekt mit einer Orientierung von 90° definiert ist. Auf diese Weise kann das trainierte Deep Learning-Modell Objekte in der Orientierung dieser beiden Referenzobjekte zählen. In diesem Fall ist es nicht erforderlich, den Trainingsparameter „Orientierungstoleranz“ anzupassen, damit die Objekte in beiden Orientierungen gezählt werden. Gleiches gilt für die Skalierung der Objekte.
Training durchführen und Ergebnisse überprüfen
Wenn Sie die Trainingsbilder mit den entsprechenden Referenzobjekten hinzugefügt und die Trainingseinstellungen überprüft haben, können Sie das Deep Learning-Modell trainieren und die Ergebnisse wie folgt überprüfen:
- Klicken Sie auf „Trainingsdaten übernehmen“, um das Training durchzuführen.
- Führen Sie die Anwendung mit mehreren Bildern aus und überprüfen Sie, ob die Objekte in allen Bildern ordnungsgemäß gezählt werden.
- Passen Sie die Suchparameter oder das Training bei Bedarf an, indem Sie beispielsweise die ROIs um die Referenzobjekte oder die Trainingsparameter geeignet ändern. Beachten Sie, dass das Training erneut durchgeführt werden muss, wenn Sie eine ROI oder einen Trainingsparameter angepasst haben.
Unterstützung von Artificial Intelligence Acceleration-Schnittstellen (AI²)
MERLIC umfasst Artificial Intelligence Acceleration-Schnittstellen (AI²) für das NVIDIA® TensorRT™ SDK und die Intel® Distribution of OpenVINO™ toolkit. Das heißt, Sie können KI-Beschleuniger-Hardware als Recheneinheit verwenden, die kompatibel mit NVIDIA® TensorRT™ oder dem OpenVINO™ toolkit ist, um optimierte Inferenzberechnungen auf der jeweiligen Hardware durchzuführen. Dadurch können Sie Deep Learning-Inferenzberechnungen erheblich beschleunigen. Die jeweilige Hardware kann beim Toolparameter „Recheneinheit“ ausgewählt werden.
Weitere Informationen zu Installation und Voraussetzungen finden Sie unter AI²-Schnittstellen für Tools mit Deep Learning.
Parameter
Standardparameter
Bild:
Dieser Parameter stellt das Bild dar, in dem die Objekte gezählt werden.
Mindestbewertung:
Dieser Parameter ist ein numerischer Wert, der die minimale Ähnlichkeit eines erkannten Objekts mit dem Referenzobjekt bestimmt. Wenn die Ähnlichkeit eines Objekts kleiner ist als der für diesen Parameter definierte Wert, wird das Objekt nicht gezählt.
Der Wert wird als reelle Zahl definiert und ist standardmäßig auf 0,5 festgelegt. Sie können die Mindestbewertung an der entsprechenden Verbindungsstelle ändern. Der Wert muss größer als 0, darf aber nicht größer als 1 sein. Je größer die „Mindestbewertung“ ist, desto geringer ist die Anzahl der Kandidaten und desto schneller ist die Suche.
Sie können die aktuelle „Mindestbewertung“ überprüfen, indem Sie die Anwendung schrittweise ausführen und prüfen, ob das Vorhandensein der Objekte in allen Bildern ordnungsgemäß ermittelt wird.
Zusätzliche Parameter
Verarbeitungsbereich:
Dieser Parameter definiert die Region für die Verarbeitung. Bildteile außerhalb der Vereinigung von ROI und „Verarbeitungsbereich“ werden nicht verarbeitet. Wenn zudem einer der Bereiche leer ist, wird der Bildteil, der innerhalb des jeweils anderen liegt, verarbeitet. Sind beide leer, wird das gesamte Bild verarbeitet.
„Verarbeitungsbereich“ ist standardmäßig als leere Region definiert. Wenn Sie eine „Verarbeitungsbereich“ angeben möchten, müssen Sie den Parameter mit einem geeigneten Ergebnis eines vorherigen Tools verbinden, damit die Region an dieses Tool übertragen wird.
ROI:
Dieser Parameter definiert die ROI für die Verarbeitung. Bildteile außerhalb der Vereinigung von ROI und „Verarbeitungsbereich“ werden nicht verarbeitet. Wenn zudem einer der Bereiche leer ist, wird der Bildteil, der innerhalb des jeweils anderen liegt, verarbeitet. Sind beide leer, wird das gesamte Bild verarbeitet.
Die ROI ist standardmäßig als leere ROI definiert. Wenn Sie eine nicht leere ROI für die Verarbeitung verwenden möchten, müssen Sie den Parameter mit einem geeigneten ROI-Ergebnis eines vorherigen Tools verbinden oder mit den verfügbaren ROI-Schaltflächen neue ROIs zeichnen.
Ausrichtungsdaten:
Dieser Parameter stellt die Ausrichtungsdaten dar, die zum Ausrichten der ROI verwendet werden. Ausrichtungsdaten sind standardmäßig nicht verbunden, sodass keine Auswirkung sichtbar ist. Wenn Sie bestimmte Ausrichtungsdaten verwenden möchten, müssen Sie den Parameter mit einem geeigneten Ergebnis eines vorherigen Tools verbinden, z. B. Ausrichtungsdaten mit Matching bestimmen, Ausrichtungsdaten mittels geradem Rand bestimmen, Bild ausrichten oder Bild drehen.
Maximale Überlappung:
Dieser Parameter definiert die maximal zulässige Überlappung der zu zählenden Objekte. Die Überlappung wird im Hinblick auf das kleinste umgebende Rechteck um das Objekt bestimmt und nicht im Hinblick auf die Fläche des Objekts selbst. Daher ist es möglich, dass zwei Objekte überlappen, obwohl ihre tatsächlichen Flächen sich nicht überschneiden.
Der Parameter wird als Prozentwert dargestellt und ist standardmäßig auf 50 % festgelegt. Das bedeutet, dass bis zu 50 % des kleinsten umgebenden Rechtecks eines Objekts im Suchbild verdeckt sein kann und das Objekt trotzdem bei der Zählung berücksichtigt wird. Sie können den Parameter auf einen Wert zwischen 0 und 100 festlegen. Wenn der Wert auf 0 festgelegt wird, ist keinerlei Überlappung zulässig, sodass nur Objekte ohne Überlappung gezählt werden. Je höher allerdings die „Maximale Überlappung“, desto höher ist das Risiko, dass falsche Objekte gefunden werden.
Recheneinheit:
Dieser Parameter definiert die Einheit, die für die Verarbeitung der Bilder verwendet wird. Der Parameter ist standardmäßig auf „auto“ festgelegt. In diesem Modus versucht MERLIC, eine geeignete GPU als Recheneinheit auszuwählen, da deren Leistung in der Regel besser ist als die der CPU. Der verfügbare Speicher in der betreffenden GPU muss jedoch mindestens 4 GB groß sein. Wird keine geeignete GPU gefunden, wird ersatzweise die CPU verwendet.
Sie können die Recheneinheit auch manuell auswählen. Klicken Sie auf den Parameter, um die Einheit in der Liste aller verfügbaren Recheneinheiten auszuwählen. Wenn Sie eine GPU als Recheneinheit auswählen, sollten Sie überprüfen, ob genügend Speicher für das verwendete Deep Learning-Modell verfügbar ist. Andernfalls kann es zu unerwünschten Effekten kommen, z. B. langsamere Inferenzberechnungen.
MERLIC unterstützt auch die Verwendung von KI-Beschleuniger-Hardware, die mit dem NVIDIA® TensorRT™ SDK oder dem OpenVINO™ toolkit kompatibel ist:
- NVIDIA®-GPUs
- CPUs, Intel®-GPUs, Intel®-VPUs (MYRIAD und HDDL), die das OpenVINO™ toolkit unterstützen
Die jeweiligen Einheiten werden mit dem Präfix „TensorRT(TM)“ oder „OpenVINO(TM)“ gekennzeichnet. Wenn Sie eine Einheit auswählen, die NVIDIA® TensorRT™ oder das OpenVINO™ toolkit unterstützt, wird der Speicher in der Einheit über das jeweilige Plugin für die AI²-Schnittstelle initialisiert.
Sobald eine KI-Beschleuniger-Hardware als Recheneinheit ausgewählt wurde, wird die Optimierung des Deep Learning-Modells gestartet. Nach der Optimierung werden alle Parameter, die Modellparameter darstellen, intern als schreibgeschützt festgelegt. Die betreffenden Werte können daher nicht mehr geändert werden, solange der ausgewählte KI-Beschleuniger als Recheneinheit verwendet wird. Um die Parameter zu ändern, müssen Sie zuerst eine andere Recheneinheit ohne KI-Beschleunigung auswählen. Nachdem die Parameter festgelegt wurden, können Sie die entsprechende KI-Beschleuniger-Hardware wieder als Recheneinheit verwenden.
CPUs, die das OpenVINO™ toolkit unterstützen, können ohne zusätzliche Installationsschritte verwendet werden. Sie werden automatisch in die Liste der verfügbaren Recheneinheiten aufgenommen. Wenn mehrere Recheneinheiten mit demselben Namen verfügbar sind, wird den Namen eine Indexnummer zugewiesen. Gleiches gilt für GPUs, die NVIDIA® TensorRT™ unterstützen.
Um GPUs und VPUs, die das OpenVINO™ toolkit unterstützen, als Recheneinheit verwenden zu können, muss die Intel® Distribution of OpenVINO™ toolkit auf dem jeweiligen Computer installiert sein. Außerdem muss MERLIC in einer OpenVINO™ toolkit-Umgebung gestartet werden. Ausführlichere Informationen zu den Voraussetzungen finden Sie unter AI²-Schnittstellen für Tools mit Deep Learning.
Neben der Optimierung über KI-Beschleuniger-Hardware unterstützt MERLIC weitere dynamische Optimierungen über das NVIDIA® CUDA® Deep Neural Network (cuDNN). Diese Optimierung kann über die MERLIC-Einstellungen im MERLIC Creator aktiviert werden. Weitere Informationen finden Sie unter MERLIC-Einstellungen.
Präzision:
Dieser Parameter legt den Datentyp fest, der intern für die Optimierung des Deep Learning-Modells für Inferenz verwendet wird, d. h., er legt die Präzision fest, mit der das Modell konvertiert wird. Die Standardeinstellung ist „hoch“.
Die folgende Tabelle zeigt die Einstellungen für die Modellpräzision, die in diesem Tool unterstützt werden.
|
Wert |
Beschreibung |
|---|---|
|
hoch |
Das Deep Learning-Modell wird mit „float32“-Präzision konvertiert. |
|
mittel |
Das Deep Learning-Modell wird mit „float16“-Präzision konvertiert. |
Die meisten Recheneinheiten unterstützen beide Präzisionseinstellungen. Es gibt jedoch u. U. auch einige Recheneinheiten, die nur eine dieser Einstellungen unterstützen. In diesem Fall ist für den Parameter nur die unterstützte Präzision verfügbar, nachdem das jeweilige Gerät mit dem Parameter „Recheneinheit“ ausgewählt wurde. Bei einer automatischen Auswahl der Recheneinheit, d. h. bei Einstellung von „Recheneinheit“ auf „auto“, ist nur die Präzision „hoch“ verfügbar.
Trainingsparameter
Die Werte der Trainingsparameter beeinflussen sowohl die Dauer des Trainings als auch die Verarbeitungszeit. Je mehr zusätzliche Trainingsbilder beim Training erstellt werden, desto länger dauert das Trainieren des Modells. Während der Verarbeitung dauert die Erkennung der zu zählenden Objekte ebenfalls länger, da das Tool die Objekte in verschiedenen Orientierungen und Skalierungsfaktoren sucht.
Standard-Trainingsparameter
Orientierungstoleranz:
Dieser Parameter beeinflusst die trainierten Orientierungen der Referenzobjekte. Er wirkt sich daher auch darauf aus, ob das trainierte Deep Learning-Modell die jeweiligen Objekte findet und zählt, wenn sie in den Suchbildern eine abweichende Orientierung aufweisen.
Der Wert wird in Grad angegeben und ist standardmäßig auf 0° festgelegt. Das bedeutet, dass die Objekte ohne jedwede Orientierungstoleranz trainiert werden und das Deep Learning-Modell Objekte im Verarbeitungsmodus nur dann zählt, wenn sie dieselbe Orientierung wie in den Trainingsbildern aufweisen. Sie können den Parameter auf einen Wert zwischen 0° und 180° festlegen.
Wenn Sie diesen Parameter anpassen, sollten Sie auch den Wert des Trainingsparameters „Orientierungstoleranzstufe“ berücksichtigen, da dieser die Abstufung der angegebenen Orientierungstoleranz im Training definiert. Beim Training werden automatisch weitere Trainingsbilder mit unterschiedlichen Orientierungen generiert. Die Werte von „Orientierungstoleranz“ und „Orientierungstoleranzstufe“ bestimmen, wie viele dieser Trainingsbilder zusätzlich generiert werden. „Orientierungstoleranz“ legt die zulässige Drehung der Objekte im Bild fest. „Orientierungstoleranzstufe“ legt fest, für welche Winkel innerhalb der angegebenen Orientierungstoleranz ein zusätzliches Trainingsbild generiert wird. Für jede Orientierungsstufe wird ein Trainingsbild mit der entsprechenden Drehung des Objekts generiert. Die generierten Trainingsbilder werden dann zusätzlich zum ursprünglichen Trainingsbild in das Training aufgenommen.
Wenn „Orientierungstoleranz“ beispielsweise auf 20 festgelegt wird, werden Objekte mit einer abweichenden Orientierung im Bereich zwischen -20° und +20° beim Training berücksichtigt. Wenn „Orientierungstoleranzstufe“ gleichzeitig auf 10 festgelegt ist, wird die angegebene Toleranz für die Orientierung beim Training in Schritten von 10° angewendet, sodass beim Training vier zusätzliche Bilder generiert werden. Diese zusätzlichen Trainingsbilder stellen das Referenzobjekt in jeweils anderen Orientierungen von -20°, -10°, 10° und 20° dar. Die Orientierung von 0° stellt die tatsächliche Orientierung des Objekts im Trainingsbild dar.
Skalierungstoleranz:
Dieser Parameter beeinflusst die trainierte Skalierung der Referenzobjekte. Er wirkt sich daher auch darauf aus, ob das trainierte Deep Learning-Modell die jeweiligen Objekte findet und zählt, wenn sie in den Suchbildern eine abweichende Skalierung aufweisen.
Der Wert wird als reelle Zahl definiert und ist standardmäßig auf 0 festgelegt. Das bedeutet, dass die Objekte ohne jedwede Skalierungstoleranz trainiert werden und das Deep Learning-Modell Objekte im Verarbeitungsmodus nur dann zählt, wenn sie dieselbe Größe wie in den Trainingsbildern aufweisen. Sie können den Parameter über die zugehörige Verbindungsstelle festlegen.
Wenn Sie diesen Parameter anpassen, sollten Sie auch den Wert des Trainingsparameters „Skalierungstoleranzstufe“ berücksichtigen, da dieser die Abstufung der angegebenen Skalierungstoleranz im Training definiert. Beim Training werden automatisch weitere Trainingsbilder mit unterschiedlichen Skalierungen generiert. Die Werte von „Skalierungstoleranz“ und „Skalierungstoleranzstufe“ bestimmen, wie viele dieser Trainingsbilder zusätzlich generiert werden. „Skalierungstoleranz“ legt die zulässige Skalierung der Objekte im Bild fest. „Skalierungstoleranzstufe“ legt fest, für welche Skalierungsfaktoren innerhalb der angegebenen Skalierungstoleranz ein zusätzliches Trainingsbild generiert wird. Für jede Skalierungsstufe wird ein Trainingsbild mit der entsprechenden Skalierung des Objekts generiert. Die generierten Trainingsbilder werden dann zusätzlich zum ursprünglichen Trainingsbild in das Training aufgenommen.
Wenn „Skalierungstoleranz“ beispielsweise auf 0,3 festgelegt wird, werden Objekte mit einem Skalierungsfaktor im Bereich zwischen -0,3 und +0,3 beim Training berücksichtigt. Wenn „Skalierungstoleranzstufe“ gleichzeitig auf 0,1 festgelegt ist, wird die angegebene Toleranz für die Skalierung beim Training in Skalierungsfaktorschritten von 0,1 angewendet, sodass beim Training sechs zusätzliche Bilder generiert werden. Diese zusätzlichen Trainingsbilder stellen das Referenzobjekt in jeweils anderen Skalierungen von -0,3, -0,2, -0,1, 0,1, 0,2 und 0,3 dar. Der Skalierungsfaktor 0 stellt die tatsächliche Größe des Objekts im Trainingsbild dar.
Zusätzliche Trainingsparameter
Orientierungstoleranzstufe:
Dieser Parameter beeinflusst die trainierten Orientierungsstufen der Referenzobjekte.
Der Wert wird in Grad angegeben und ist standardmäßig auf 5° festgelegt. Sie können den Parameter auf einen Wert zwischen 0° und 180° festlegen. Wenn der Wert von „Orientierungstoleranz“ auf 0 festgelegt ist, hat dieser Parameter keine Auswirkung.
Dieser Parameter sollte nur unter Beachtung des Trainingsparameters „Orientierungstoleranz“ geändert werden, weil sich die Orientierungsstufen auf den in „Orientierungstoleranz“ definierten Toleranzwert beziehen. Für jede Orientierungsstufe innerhalb des in „Orientierungstoleranz“ definierten Bereichs wird ein Trainingsbild mit der entsprechenden Drehung des Objekts generiert. Weitere Informationen zur Auswirkung der Kombination der beiden Trainingsparameter auf das Training finden Sie in der Beschreibung des Parameters Orientierungstoleranz.
Skalierungstoleranzstufe:
Dieser Parameter beeinflusst die trainierten Skalierungsstufen der Referenzobjekte.
Der Wert wird als reelle Zahl definiert und ist standardmäßig auf 0,1 festgelegt. Das bedeutet, dass die definierte „Skalierungstoleranz“ für das Training in Skalierungsstufen mit dem Faktor 0,1 berücksichtigt wird. Sie können den Wert über die zugehörige Verbindungsstelle ändern. Wenn der Wert von „Skalierungstoleranz“ auf 0 festgelegt ist, hat dieser Parameter keine Auswirkung.
Dieser Parameter sollte nur unter Beachtung des Trainingsparameters „Skalierungstoleranz“ geändert werden, weil sich die Skalierungsstufen auf den in „Skalierungstoleranz“ definierten Toleranzwert beziehen. Für jede Skalierungsstufe innerhalb des in „Skalierungstoleranz“ definierten Bereichs wird ein Trainingsbild mit der entsprechenden Skalierung des Objekts generiert. Weitere Informationen zur Auswirkung der Kombination der beiden Trainingsparameter auf das Training finden Sie in der Beschreibung des Parameters Skalierungstoleranz.
Standardergebnisse
Anzahl:
Dieses Ergebnis gibt die Anzahl der Objekte aus, die mit den aktuellen Parametereinstellungen gezählt wurden. Die Ausgabe erfolgt als Ganzzahl.
Bewertung:
Dieses Ergebnis gibt die ermittelte Bewertung der einzelnen gezählten Objekte aus. Dabei handelt es sich um eine reelle Zahl, die den Grad der Übereinstimmung des gezählten Objekts mit dem Trainingsmodell angibt. Wurde mehr als ein Objekt im Bild gezählt, werden die zugehörigen Bewertungen in einem Tupel ausgegeben.
Toolstatus:
„Toolstatus“ gibt Informationen zum Status des Tools aus und kann daher für die Fehlerbehandlung verwendet werden. Weitere Informationen zu den verschiedenen Toolstatus-Ergebnissen finden Sie unter Toolstatus-Ergebnis.
Zusätzliche Ergebnisse
Objektlage:
Dieses Ergebnis gibt die Regionskonturen der gezählten Objekte aus.
Orientierungspfeil:
Dieses Ergebnis gibt die Pfeile aus, die die Orientierung des Modells angeben, das beim Training generiert wurde. Die Ausgabe erfolgt als Kontur.
X:
Dieses Ergebnis gibt die X-Koordinaten der gezählten Objekte aus. Die ausgegebenen X- und Y-Koordinaten entsprechen den Mittelpunkten der in „Objektlage“ ausgegebenen Regionskonturen.
Y:
Dieses Ergebnis gibt die Y-Koordinaten der gezählten Objekte aus. Die ausgegebenen X- und Y-Koordinaten entsprechen den Mittelpunkten der in „Objektlage“ ausgegebenen Regionskonturen.
Verwendete Recheneinheit:
Dieses Ergebnis gibt die Recheneinheit aus, die in der letzten Iteration verwendet wurde. Anhand dieses Ergebnisses können Sie feststellen, welche Recheneinheit tatsächlich verwendet wurde, wenn der Parameter „Recheneinheit“ auf „auto“ festgelegt ist, bzw. überprüfen, ob die richtige Recheneinheit verwendet wurde.
Datentyp der Präzision:
Dieses Ergebnis gibt den Datentyp aus, der intern für die Optimierung des Deep Learning-Modells für Inferenz verwendet wurde. Anhand dieses Ergebnisses können Sie überprüfen, ob die richtige Präzision verwendet wurde, falls Probleme auftreten.
Wenn der Parameter „Präzision“ auf „hoch“ festgelegt ist, soll das Deep Learning-Modell mit „float32“-Präzision konvertiert werden. Daher wird erwartet, dass dieses Ergebnis den Datentyp „float32“ ausgibt. Wenn der Parameter „Präzision“ auf „mittel“ festgelegt ist, soll das Deep Learning-Modell mit „float16“-Präzision konvertiert werden. In diesem Fall werden für das Ergebnis Werte des Datentyps „float16“ erwartet. Falls bei einer Iteration Ihrer MVApp ein Problem aufgetreten ist, können Sie überprüfen, ob dieses Ergebnis einen anderen Datentyp als erwartet ausgibt. Weitere Informationen finden Sie möglicherweise auch in der Log-Datei. Weitere Informationen zu den Log-Dateien finden Sie auf der Seite Protokollieren.
Verarbeitungszeit:
Dieses Ergebnis gibt die Dauer der letzten Ausführung des Tools in Millisekunden aus. Das Ergebnis wird als zusätzliches Ergebnis bereitgestellt. Es ist daher standardmäßig ausgeblendet, kann aber über die Schaltfläche ![]() neben den Toolergebnissen angezeigt werden. Weitere Informationen finden Sie im Abschnitt Verarbeitungszeit in der Tool-Referenz-Übersicht.
neben den Toolergebnissen angezeigt werden. Weitere Informationen finden Sie im Abschnitt Verarbeitungszeit in der Tool-Referenz-Übersicht.
Anwendungsbeispiele
Dieses Tool wird in den folgenden MERLIC-Vision-App-Beispielen verwendet:
- count_bottles_with_deep_learning.mvapp

