Find Objects
Use this tool to locate and classify objects in an image based on a pre-trained deep learning model. You can use deep learning models for object detection or instance segmentation.
Both the object detection model and the instance segmentation model detect objects of given classes and find them in the image. The objects can be orientated in any direction and they may also partially overlap. The location of each detected object will be marked with a so-called bounding box, a rectangle surrounding the respective object. For each bounding box, a confidence value is returned that expresses how likely the object in the bounding box belongs to the assigned class. Instance segmentation is a special case of object detection where the model also predicts different object instances and assigns the found instances to their region in the image. Therefore, you can also get the pixel-precise regions of the detected objects in addition to their bonding boxes and confidence values.
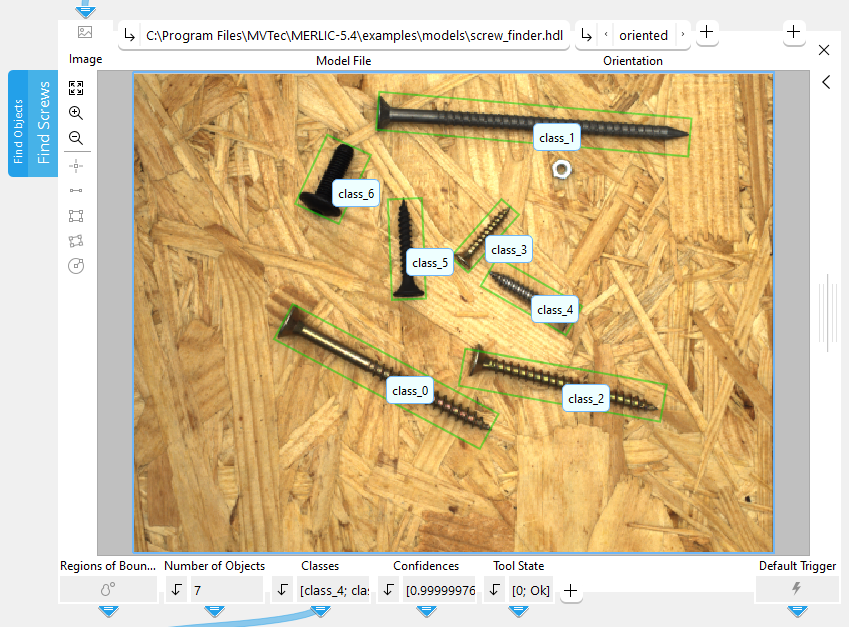
If a deep learning model file is available, you can immediately use it in this MERLIC tool. Otherwise, you first have to train a model.
Training the Deep Learning Model
You can use MVTec's Deep Learning Tool to train the deep learning model for this tool. When creating a new project for the training, you have to select the desired deep learning method. If you want to train a deep learning model for this tool, you can choose between the following methods:
|
Deep learning method |
Description |
|---|---|
|
Axis-aligned object detection
|
This method marks the location of each detected object with a bounding box that is oriented parallel to the coordinate axes. Therefore, it is particularly suitable for objects whose shape can be easily enclosed by an axis-aligned rectangle, such as bottle caps. You can use this method if you are only interested in the location of the objects but not in their orientation. In addition, you can save time on labeling because axis-aligned bounding boxes are less complex to work with.
|
|
Oriented object detection |
This method marks the location of each detected object with an oriented bounding box. Therefore, it is particularly suitable for tilted objects whose shape cannot be optimally enclosed by an axis-aligned rectangle, such as diagonally lying pencils. You can use this method if you are not only interested in the location of the detected objects but also in their orientation. The respective bounding boxes will be oriented accordingly. With this method, your results will be more accurate. However, you will need more time for labeling because oriented bounding boxes are more complex to work with.
|
|
Instance segmentation
|
This method marks the location of each detected object with a bounding box that is oriented parallel to the coordinate axes. In addition, the region of each detected object instance is predicted and returned. You can used this method if you want to distinguish between multiple instances of the same class and visualize the pixel-precise regions of the object instances in the image.
|



After choosing the deep learning method, the workflow is usually as follows:
- Create the label classes.
- Assign the labels to your images, objects, or regions. In case of an instance segmentation model, you also have to create instances based on polygons or masks.
- Train the model.
The trained deep learning model can then be used in this MERLIC tool as input at the parameter "Model File".
While it is also possible to use MVTec HALCON to train the deep learning model, it is recommended to use the MVTec Deep Learning Tool. For more information on how to create a deep learning model, please refer to the documentation of the MVTec Deep Learning Tool.
Support of Artificial Intelligence Acceleration Interfaces (AI²)
MERLIC comes with Artificial Intelligence Acceleration Interfaces (AI²) for the NVIDIA® TensorRT™ SDK and the Intel® Distribution of OpenVINO™ toolkit. Thus, you can use AI accelerator hardware as processing unit that is compatible with the NVIDIA® TensorRT™ or the OpenVINO™ toolkit to perform optimized inference on the respective hardware. This way, you can achieve significantly faster deep learning inference times. The respective hardware can be selected at the tool parameter "Processing Unit".
For more information on the installation and the prerequisites, see the AI² Interfaces for Tools with Deep Learning.
Parameters
Basic Parameters
Image:
This parameter represents the image in which objects should be detected.
Model File:
This parameter defines the deep learning model (.hdl file format) that should be used for detecting objects. By default, no model is defined. However, it is necessary to define a deep learning model to use this tool.
If you want to use a specific AI accelerator hardware supported by MERLIC's AI² interfaces, you can use a deep learning model that was optimized for the respective device. This improves the loading time of the MVApp and reduces the amount of memory that is needed for the model.
We recommend using the MVTec Deep Learning Tool to train the model. When exporting the model, you can choose to optimize the model for an AI² interface. However, if you still want to use MVTec HALCON for the training, you have to consider the following restrictions for the preprocessing parameters.
This tool only supports deep learning models that were trained with the default values for the following preprocessing parameters:
- NormalizationType = "none"
- DomainHandling = "full_domain"
Orientation:
This parameter allows you to specify the orientation that determines the resulting bounding boxes. If you are using an object detection model that was trained with oriented bounding boxes, this parameter allows you to align the resulting bounding boxes axis-aligned instead. However, if your model was trained with axis-aligned bounding boxes, the orientation of the bounding boxes cannot be changed. Therefore, the parameter will be deactivated and the value will be grayed out.
By default, the parameter is set to "axis-aligned".
|
Value |
Description |
|---|---|
|
axis-aligned |
The bounding boxes are provided as axis-aligned rectangles. When using this setting, all values returned in the "Angles" result will be 0.0. |
|
oriented |
The bounding boxes are provided as oriented rectangles. This parameter value can only be set when using a model file that was trained for oriented object detection. |
Additional Parameters
Class Selector:
This parameter filters the results. You can choose between three different filter options. By default, the parameter is set to "all classes".
|
Value |
Description |
|---|---|
|
all classes |
The tool detects all available classes. |
|
only class <class name> |
The tool only detects the selected class. The selected class can be chosen out of all available classes. |
|
all w/o <class name> |
The tool detects all available classes except for the selected one. The selected class can be chosen out of all available classes. |
Maximum Number of Objects:
This parameter defines the maximum number of objects that can be detected by the deep learning model. You can use this parameter to override the respective value that was used during the training of the deep learning model.
The parameter is automatically set to the maximum value stored in the model file on model file load. To use a different value, enter the desired maximum number of objects into the input field of the parameter or use the slider to set the value. The slider can only be used to set values up to 20. If you want to find more than 20 objects, enter the value manually into the input field.
The objects will be sorted in order of their confidence values. If the number of objects in an image is higher than the value defined in this parameter, the objects with the lowest confidence will be excluded until the amount of detected objects matches the value defined in "Maximum Number of Objects".
In the result "Number of Objects", you can see how many objects were detected in an image.
Minimum Confidence:
This parameter determines the minimum confidence an object must reach in order to be detected. All objects with a confidence value that is lower than the defined "Minimum Confidence" are not detected. The parameter is set to 0.5 by default.
Overlap of Same Classes:
This parameter sets the maximum allowed overlap of detected objects of the same class. This means that if two objects of the same class overlap, and this overlap exceeds the value of the parameter "Overlap of Same Classes", the object with the lower confidence will not be detected. This is helpful if your object detection model finds several promising instances for the same object or if two of the same objects are very close to each other. The parameter is set to 0.5 by default.
Overlap of Different Classes:
This parameter sets the maximum allowed overlap of detected objects of different classes. This means that if two objects with different classes overlap and this overlap exceeds the value of the parameter "Overlap of Different Classes", the object with the lower confidence will not be detected. The parameter is set to 1 by default.
Processing Unit:
This parameter defines the device used for processing the images. The parameter is set to "auto" by default. In this mode, MERLIC tries to choose a suitable GPU as processing unit because it usually performs better than the CPU. However, this requires at least 4 GB of available memory on the respective GPU. If no suitable GPU is found, the CPU is used as fallback.
You can also choose the processing unit manually. Click on the parameter to select the device from the list of all available processing units. If you are choosing a GPU as processing unit, we recommend to check that enough memory is available for the used deep learning model. Otherwise, undesirable effects such as slower inference times might occur.
MERLIC also supports the use of AI accelerator hardware that is compatible with the NVIDIA® TensorRT™ SDK or the OpenVINO™ toolkit:
- NVIDIA® GPUs
- CPUs, Intel® GPUs, Intel® VPUs (MYRIAD and HDDL) with support of the OpenVINO™ toolkit
The respective devices are marked either with the prefix "TensorRT(TM)" or "OpenVINO(TM)". If you select a device that supports NVIDIA® TensorRT™ or the OpenVINO™ toolkit, the memory will be initialized on the device via the respective plug-in for the AI² interface.
As soon as an AI accelerator hardware has been selected as processing unit, the optimization of the deep learning model is started. After the optimization, all parameters that represent model parameters will be internally set to read-only. Thus, their values cannot be changed anymore as long as the selected AI accelerator is used as processing unit. To change the parameters, you first have to change the processing unit to a different one without any AI acceleration. After setting the parameters, you can set the processing unit back to the respective AI accelerator hardware.
CPUs with support of the OpenVINO™ toolkit can be used without any additional installation steps. They will be automatically available in the list of available processing units. If multiple processing units with the same name are available, an index number is assigned to their name. The same applies to GPUs with support of the NVIDIA® TensorRT™.
To use GPUs and VPUs with the support of the OpenVINO™ toolkit as processing unit, the Intel® Distribution of OpenVINO™ toolkit must be installed on your computer and MERLIC must be started in an OpenVINO™ toolkit environment. See the topic AI² Interfaces for Tools with Deep Learning for more detailed information on the prerequisites.
Besides the optimization via AI accelerator hardware, MERLIC supports further dynamic optimizations via the NVIDIA® CUDA® Deep Neural Network (cuDNN). This optimization can be enabled via the MERLIC preferences in the MERLIC Creator. For more information, see the topic MERLIC Preferences.
Precision:
This parameter defines the data type that is used internally for the optimization of the deep learning model for inference, that is, it defines the precision to which the model is converted to. The offered data types depend on the selected processing unit. It is set to "float32" by default.
There might be some processing units that support only one data type. In this case, only the supported data types will be available at the parameter as soon as the respective device has been selected at the parameter "Processing Unit". If the processing unit is selected automatically, that is, if "Processing Unit" is set to "auto", only the data type "float32" is available.
Results
Basic Results
Regions of Bounding Boxes:
This result returns the bounding boxes of the detected objects as regions.
Number of Objects:
This result returns the number of detected objects regardless of their class.
Classes:
This result returns the class names of all detected objects. They are returned as a tuple in order of their confidence. It contains the same number of strings, i.e., classes, as the value of the result "Number of Objects".
Confidences:
This result returns a numeric value that indicates how likely the detected objects belong to the classes assigned to them. If the parameter has the value 1, the found object matches the trained class with an accuracy of 100%. If more than one object is found, the corresponding confidences are returned as a tuple in order of their confidence.
Tool State:
"Tool State" returns information about the state of the tool and thus can be used for error handling. For more information, see Tool State Result
Additional Results
Contours of Bounding Boxes:
This result returns the bounding boxes of the detected objects as contours.
Object Instances:
This result returns the regions of the detected object instances. They are returned ordered by their confidence.
The regions are only determined if a deep learning model for instance segmentation is used. If an object detection model is used, this result is empty.
X:
This result contains the X coordinates of the center points of the bounding boxes of all the detected objects. They are defined in pixels and returned as a tuple in order of their confidence. It contains the same number of X coordinates as the value of the result "Number of Objects".
Y:
This result contains the Y coordinates of the center points of the bounding boxes of all the detected objects. They are defined in pixels and returned as a tuple in order of their confidence. It contains the same number of Y coordinates as the value of the result "Number of Objects".
Angles:
This result returns the angles of the detected objects' bounding boxes. They determine how much and in which direction the bounding boxes are rotated. The angles are returned in degrees as real numbers and as a tuple in order of their confidence. The tuple contains the same number of angles as the value of the result "Number of Objects".
|
Value |
Description |
|---|---|
|
0 |
The rectangle is not rotated. |
|
1 to 180 |
The rectangle is rotated in counterclockwise direction. |
|
−1 to −180 |
The rectangle is rotated in clockwise direction. |
This result only returns angles between -180° and 180° when using a model file that was trained for oriented object detection. If the model file was trained with a deep learning method that supports only axis-aligned bounding boxes, all values in the resulting tuple will be 0.0.
Used Processing Unit:
This result returns the processing unit that was used in the last iteration. You can use this result to check which processing unit was actually used if the parameter "Processing Unit" is set to "auto" or to check that the correct one was used.
Precision Data Type:
This result returns the data type that was used internally for the optimization of the deep learning model for inference. You can use this result to check if the correct precision was used in case any problems occur.
If a problem occurs during an iteration of your MVApp, you could check if this result returns a different data type than expected and also have a look at the log file for more details. For more information, see Logging.
Processing Time:
This result returns the duration of the most recent execution of the tool in milliseconds. The result is provided as additional result. Therefore, it is hidden by default but it can be displayed via the ![]() button beside the tool results. For more information see the section Processing Time in the tool reference overview.
button beside the tool results. For more information see the section Processing Time in the tool reference overview.
Application Examples
This tool is used in the following MERLIC Vision App examples:
- find_and_count_screw_types.mvapp
- segment_pills_by_shape.mvapp

