自 2012 年以来,深度学习与机器视觉一直成功地携手并进。这个故事始于基于卷积神经网络架构的 AlexNet。如今,尽管自 2012 年以来许多方面已经发生了变化,深度学习已确立自己作为机器视觉不可或缺的一部分。例如,利益相关者和科学出版物的数量大幅增加,AI 模型架构的复杂性也显著提高。另一个趋势是,数据集的规模和用于训练和推理的硬件性能不断提升。此外,像 ChatGPT 这样的新型强大 AI 模型正在占领市场。
另一方面,深度学习在工业生产领域变得越来越热门,应用越来越广泛,对合格数据科学家和受过良好训练的深度学习专家的需求也随之增加。此外,由于硬件速度的不断提高和专用深度学习加速器的出现,算法的性能达到了前所未有的水平——极大地提升了人们对这项技术的信心。
尽管人们对深度学习充满热情,但在实际应用中,仍有许多挑战需要克服。例如,训练通常需要大量的示例图像数据。处理这些数据需要大量工作和相应的高成本,这往往是中小企业 (SMEs) 难以承受的。特别是,由于生产质量已经很高,缺陷物体的图像(所谓的“坏图像”)数量不足。
另一个挑战是深度学习非常耗费资源。生产系统中常见的传统处理器(CPU)并不总是具有足够的计算能力,这使得使用大型数据集进行现场训练几乎不可能。
MVTec 正在通过两项新开发的技术来应对这些挑战,这些技术将于2024年推出:
首先,功能的 “不确定性估计” 将帮助可靠地检测变化。这些变化可以包括光照波动、新的缺陷类型、生产系统磨损、检查期间的物体修改或“黑天鹅”事件。
深度学习应用只能在其训练框架内理解世界。当出现变化时,模型仍会基于已知标准评估图像。例如,如果出现了一种新类型的错误(没有训练过的标准)或完全不同的物体,系统将面临挑战:它试图将修改后的情况归类到已知类别,但由于标准未知而无法成功。这时,不确定性估计功能派上用场:作为对分类的补充测试实例,该技术通过现实的估计来验证决策的不确定性。
在这方面的决定性因素是新模型是否位于基础数据集的特征分布内。如果检查的图像仅与训练数据集略有不同,不确定性估计会将其标记为“近分布”。在实践中,这可以通过黄色指示灯来显示,以触发手动检查。另一方面,如果对象在特征分布之外,则将其归类为“超出分布”,这可以通过红色指示灯来显示。如果这种情况变得更加频繁,很明显训练数据集已不再代表检查任务。在这种情况下,需要进行后期训练。然而,这种后期训练通常既耗时又耗资源。通常需要 GPU,而这在适用系统中通常并不可用。为了减少硬件需求和训练时间,后期训练应尽可能仅需少量新图像即可完成。但这也带来了挑战,因为与人类类似,系统往往会高估新信息的价值。虽然模型成功地分类了新案例,但忽视了旧图像,这可能导致错误。
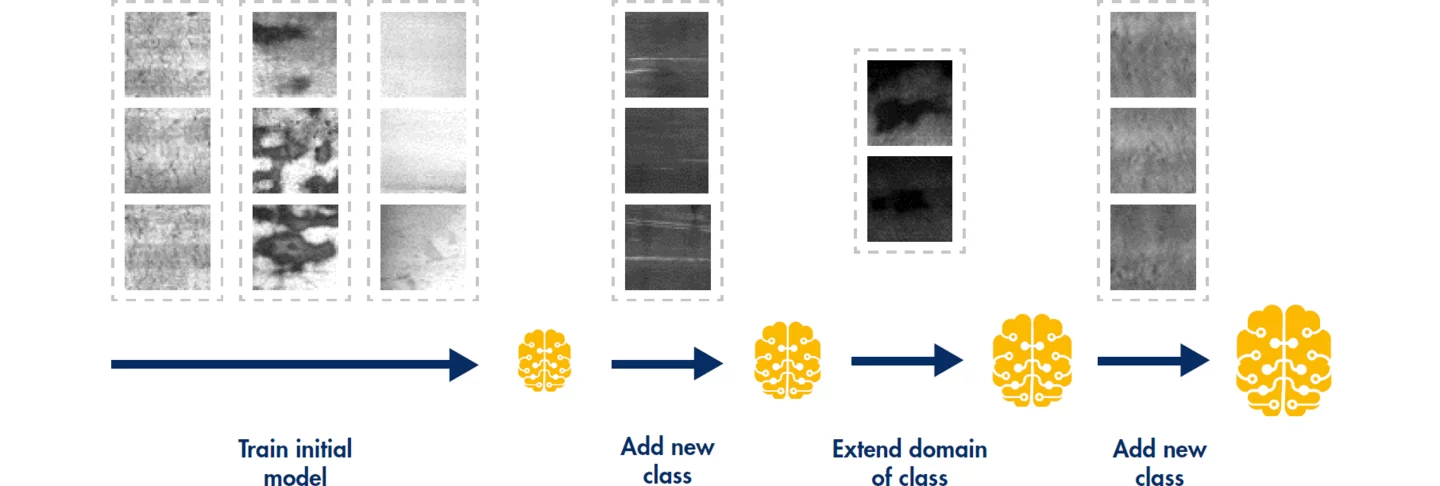
为了减少后训练涉及的工作量并确保稳健的检测率,MVTec 开发了“持续学习”的新功能。该功能可以仅用少量图像对现有模型进行后训练。
常规 CPU 的计算能力足以完成此任务,从而使训练可以直接在系统上进行。根据图像数量和可用计算能力,训练可能只需几秒钟。新图像可以轻松添加到现有或新类别中。无需深入的机器视觉专业知识,用户通常可以自行在机器上进行后训练。这使公司能够显著减少后训练的工作量,加快整个过程,并降低成本。
深度学习在工业价值链中的重要性日益增加。为了使这项技术跟上不断增长的需求,并保持对企业的可用性,它需要不断发展。为此,MVTec 提供了两个新功能“不确定性估计”和“持续学习”。这些功能能使生产现场可靠地检测和快速响应变化和新条件。因此,这两项技术不仅提升了对深度学习的信心,也加强了其在工业生产领域的应用。