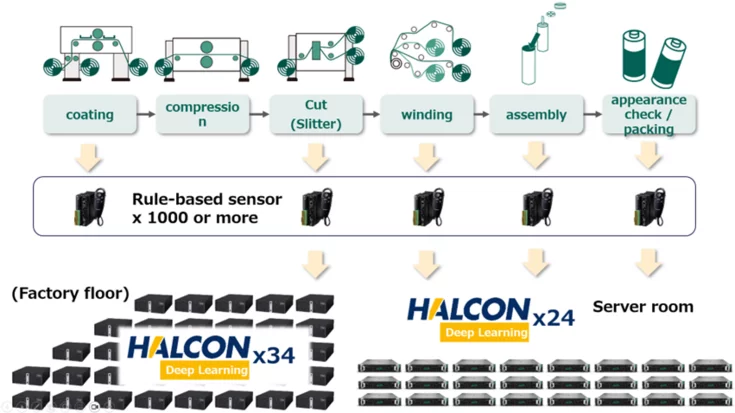
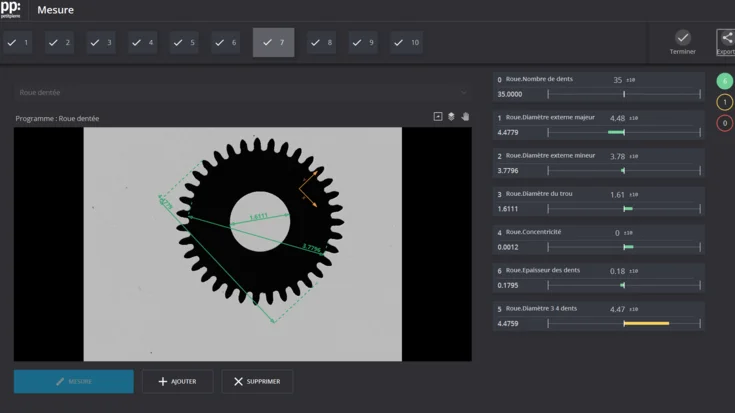
In the pharmaceutical industry, strict compliance regulations require medical product packaging to be correctly labeled before delivery. To meet these requirements, the Chinese company Shenzhen Jiangrun Xuneng Technology has developed a powerful mach…
HALCON
Medical Supplies & Pharmaceutical
Bar Code & 2D Code Reading
OCR