Developers Corner
You want your new deep learning application to be successful? Then you should be careful with your data handling. In every machine vision application it is important to work with “high-quality” image data. However, in case of deep learning applications, this statement is even more important.
No matter which method, resp. feature, you are using - classification, object detection, segmentation, or anomaly detection - the deep learning networks have to be trained by data in all methods. Keep in mind: Each deep learning network can only learn what it sees!
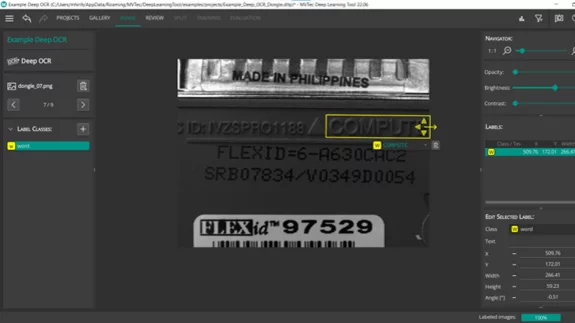
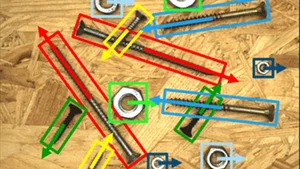
Beside the acquired image data, the second very important part of the data set is the labeling of the data. Of course the labeling has to be correct, but it also has to be accurate. Especially for object detection and segmentation, an accurate labeling is essential for an accurate localization in the online process. Again, the network can only learn the accuracy which is given in the labeled training set. It is also very important that the labeling is extremely consistent. You have to label every object in the data set and every object within one class in the same way.
The correctness of the labeling seems obvious and simple. However, in case of hundreds of labeled object, it is not uncommon that errors, i.e., wrongly labeled data, occur. In this case, the new Review tab in the MVTec Deep Learning Tool is very well suited to find the mislabeled data very fast. So take a look into this new feature and get rid of your erroneous data.