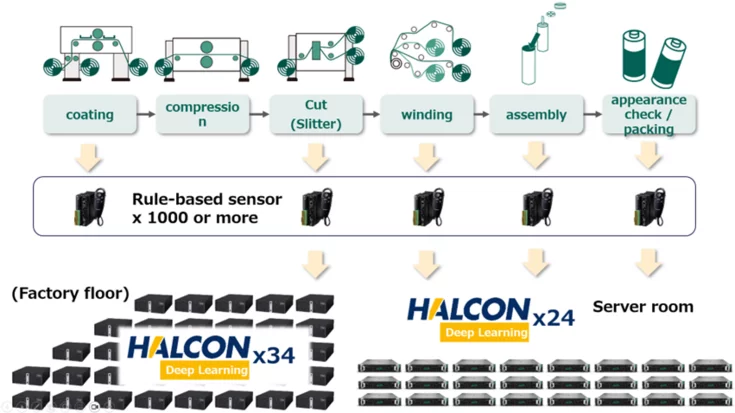
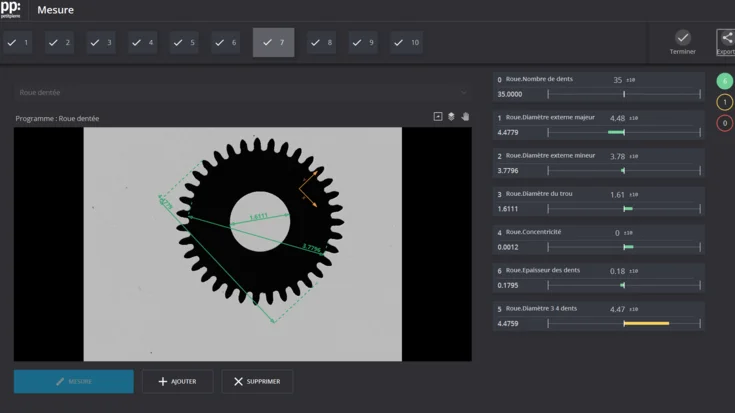
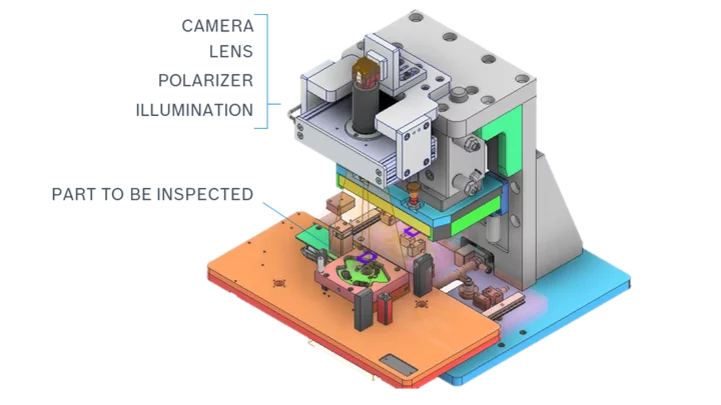
December 30, 2021 | Developers Corner
Deep OCR outperforms the classical approaches in many ways. The most obvious point is the better recognition rate. But also, the independence of the font type, the polarity and the orientation of the text are strong arguments for Deep OCR. In this article we will show you some tips and tricks how to further improve your Deep OCR results.
First, you should take your time to think about the mode which is suitable for your application. In Deep OCR two modes are available: ‘detection’ and ‘recognition’. The mode ‘detection’ finds connected characters as words in the image and gives you the bounding box of the word. The mode ‘recognition’ translates cropped images in machine-readable text.

In a lot of applications, both modes ‘detection’ and ‘recognition’ are needed. In this case you can use the mode 'auto'. Have in mind that HALCON provides a powerful toolbox to write your own algorithm to detect the text you are interested in. This could be very useful, if you are only interested in specific text lines in an image full of text, or if you would like to decrease your runtime.
In the following we give you some hints how to improve your Deep OCR performance in case of the modes ‘detection’ and ‘recognition’. But before evaluating the results, you should look at your image data and think about preprocessing methods such as enhancing the contrast.
If you want to improve your ‘detection’ result, you should take a look into the score maps. You can find the score maps in the DeepOcrResult handle. Especially, the character score map and the link score map can give you useful insights about the ‘detection’ results. This information could be used to adapt the important parameters ’detection_min_word_score’ and ‘detection_min_character_score’.
If your text is already horizontally aligned, set the parameter ‘detection_orientation’ = 0 and you will not have any issues with imperfectly aligned rectangles.
In case of large images with small text use the powerful parameter ‘detection_tiling’. Setting this parameter to 'true' splits the images internally into tiles. The tilling is done fully automatically, and you don't have to care about the tiled images, but you can simply enjoy the detected text. However, bear in mind that the runtime will increase, depending on the size of the processed image.
If you are surprised by the results you get from the recognition mode, we recommend opening the DeepOcrResult handle and take a look into the preprocessed image which is used for the recognition. In many cases this image gives you already an explanation, why the ‘recognition’ fails. The most common issue is the length of the text line, which can be handled by setting the parameter 'recognition_image_width'. A detailed example can be found in the standard example ‘deep_ocr_workflow.hdev’.
Finally, it is always worth to reconsider whether Deep OCR is the right choice. Even if Deep OCR outperforms the rule-based approaches, there are still use cases (speed restrictions, specific font types, hardware limitations or pixel-precise segmentation) which justify the choice of classical approaches.
Published on: December 30, 2021