Deep learning and machine vision have gone successfully hand in hand since 2012: The story began with AlexNet, an architecture based on a convolutional neural network. Today, deep learning has established itself as an integral part of machine vision although many aspects have changed since 2012. For example, the number of stakeholders and scientific publications has grown greatly, and the complexity of AI model architectures has increased enormously. A further trend is that datasets and the performance of hardware for training and inference are constantly increasing in size. Furthermore, new and powerful AI models such as ChatGPT are conquering the market.
Deep learning, on the other hand, is becoming increasingly popular in the field of industrial production and used in ever more applications. This is, in turn, increasing the need for qualified data scientists and well-trained deep learning experts. Furthermore, thanks to ever-faster hardware and specialized deep learning accelerators, the performance of the algorithms is reaching an unprecedented level – giving a huge boost to people’s confidence in the technology.
Despite all the euphoria, in practice, there are still a number of challenges that need to be overcome when using deep learning. For example, training usually requires extremely large data volumes in the form of example images. Processing these involve large amounts of work and accordingly high costs, which small and medium-sized enterprises (SMEs) often struggle to afford. In particular, not enough images of defective objects, so-called “bad images”, are available due to their rarity in the case of already high production quality.
A further challenge is that deep learning tends to be very resource hungry. Conventional processors (CPUs), as often found in production systems, do not always have enough computing power, which makes in-the-field training with large datasets almost impossible.
MVTec is addressing these challenges with two newly developed technologies that will be available from 2024:
Firstly, the feature “uncertainty estimation” will help to reliably detect changes. Such changes can include lighting fluctuations, new defect types, production system wear, modified objects during inspections, or black swans.
Deep learning applications can only understand the world within the framework in which they have been trained. In the case of changes, the model continues to assess the images based on the known criteria. If, for example, a new type of error (for which no criteria have been trained) or a completely different object appears, the system faces challenges: It tries to allocate the modified conditions to a known category but fails as the criteria are unknown. This is where uncertainty estimation comes in: As a testing instance that complements classification, the technology uses a realistic estimation to validate the uncertainty of the decision.
A decisive factor in this regard is whether the new model lies within or outside the feature distribution of the underlying dataset. If the inspected image only differs from the training dataset slightly, uncertainty estimation marks it as “near distribution”. In practice, this can be indicated by a yellow light for example, to trigger a manual inspection. If, on the other hand, the object lies outside the feature distribution, it is classed as “out of distribution”, which can in turn be indicated by a red light. If such cases become more frequent, it is clear that the training dataset is no longer representative of the inspection task. In this case, post-training is required. However, such post-training is often both time and resource consuming. A GPU, which is not usually available on the applicable system, is normally required. To reduce the hardware requirements and the training time, post-training should be possible with just a few new images. This poses a challenge though as, similarly to humans, the system tends to overvalue new information. While the model successfully classifies the new cases, it neglects the old images, which can lead to errors.
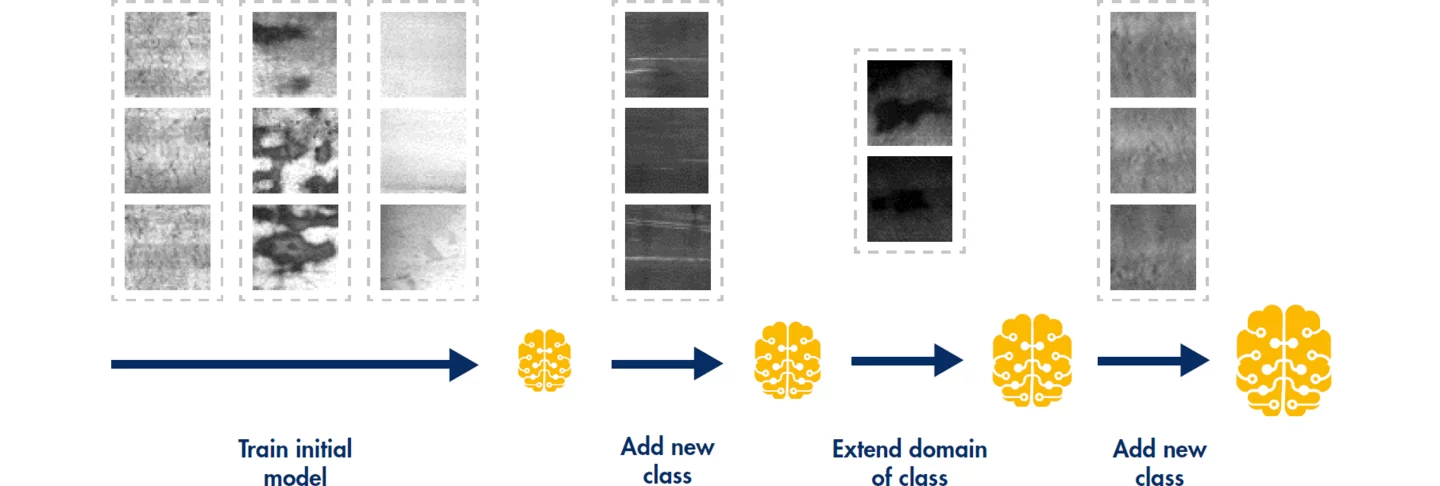
To reduce the amount of work involved with post-training and ensure a robust detection rate, MVTec has developed its new feature “continual learning”. This can be used to posttrain an existing model with a small number of images.
The capacity of a conventional CPU suffices to do this, enabling training to occur on the system directly. Depending on the number of images and the available computing power, training can take just a few seconds. New images can be easily added to an existing or a new class. No in-depth machine vision expertise is required, so users can generally perform the post-training on the machine themselves. This enables companies to drastically reduce the post-training workload, speed up the process as a whole, and reduce costs.
Deep learning is becoming ever more important for industrial value chains. For the technology to keep pace with growing requirements and remain a usable option for companies, it requires continual further development. MVTec is providing its two new features “uncertainty estimation” and “continual learning” to this end. These pave the way for reliably detecting and quickly responding to changes and new conditions directly on the shop floor. As such, the two technologies boost confidence in deep learning and therefore strengthen its use in the field of industrial production.